
CC0 パブリックドメイン
May 15, 2025
柴田 淳 A_Shibata
株式会社マインドインフォ 代表取締役。東進デジタルユニバーシティ講師。著書に『みんなのPython 第5版』『Pythonで学ぶはじめてのプログラミング入門教室』など。理系の文系の間を揺れ動くヘテロパラダイムなエンジニア。
AIコーディング・アシスタントとプログラミングをしていると、よく「AIが生成するバグ」に遭遇します。バグなので直さなければならないのですが、AIが産み出したバグを人間が指摘して直してもらったり、またしばしば人間が直接修正したりするのは大変不本意で本末転倒な気がします。そもそもバグのないプログラムを作ってもらう「つもり」でAIを使っているのではなかったのか、と思うからです。
でも、そうやってAIのバグを直しながらあれこれ考えているうちに、これはもしかすると「新しい学びの体験」なのではないか、と思うようになりました。今回は、数学と地続きの「バグ」について辿りながら、AIとプログラミング、そして学びの未来について、考えてみたいと思います。
まるで人間のように言葉を操る高度なAIが使える現代であっても、コンピュータの中で行われていることは「計算」です。私たちは「知るために計算する」という時間線に生きていて、AIはその延長線上に生まれた存在に他なりません。
コンピュータが存在しなかった時代、計算は「計算手」と呼ばれる人間が行っていました。その頃解決すべき課題は「ヒューマンエラー」で、今のデバッグに相当する作業として行われていたのは「検算」でした。同じ結果を出す別の方法を使って計算をしたり、同じ計算を複数チームで回したりして、計算が正しいかどうかを確認する作業を必ず組み込んでいました。
第二次世界大戦中、軍事目的で行われる計算の量が増えると、やがて機械式の計算機が開発され、プログラム内蔵式の計算機の発明に繋がります。機械によってアトミックな計算が正確行われるようになったのですが、今度は「計算の手順」が正しいかどうかを確かめる手順が必要になりました。計算手順がさらに抽象化され「プログラミング言語」が誕生すると、今日的な意味に近いデバッグが行われるようになります。
軍や研究機関で動いていた最初期のプログラムの開発、デバッグを行っていたのは、かつて計算手として働いていた女性であったということは前々回にも書きましたね。対象が計算であれプログラムであれ、結果が正しいことを確認しながら必要に応じて手順を修正する、という作業の根にある思想は、検算も初期のデバッグも同じなのです。
「FORTRAN」のような最初期のプログラミング言語で実行されていたことのほとんどは純粋な計算でした。入力されたデータを使って方程式を解いたり、方程式を作るための方程式を解くための計算をするのが当時のプログラムの主な目的でした。当時のデバッグとは、入力値に対して計算された結果が正しいことを確かめるというもので、今のデバッグとは違った作業だったようです。
コンピュータが小型化し高機能化すると、周辺に様々な機器が接続されるようになります。それまで計算だけを行っていたプログラムは、周辺機器の「制御」を行うようになります。「制御手順」をプログラムで扱うようになり、デバッグも複雑化してゆきます。
キーボードを例にして考えましょう。キーボードから送られてくる生のデータは、文字そのものではありません。コントロール用のICが送る「制御用の数値」が送られてくるのです。「キーコード」などと呼ばれるこの数値は、いわばキーボードの「状態」を表現するためのハードウエア寄りの数値集合です。これをプログラムで利用するには、コンピュータ上で使われる「ASCII」のような文字集合に変換するプログラムを用意する必要があります。
また、単純に変換しただけでは、期待されるキーの操作にはならず「バグ」になってしまいます。文字キーが押され続けている限り同じコードが送られて「キーリピート」状態になってしまうからです。連続して同じキーが押されている限り1回の入力と見なし、一定時間押され続けていたらキーリピートに切り替える、という「状態変化」を組み込んだ手順をプログラムにすることで「デバッグ」の完了です。キーボードをアクションゲームの入力として使う場合は、キーが連続して押されていることを判別する別の手順が必要になりますし、複数のキーが押されていることを判定する同時押しの判定もしないと「バグ」になります。
システムを自動運用するための「手順の実行」にコンピュータが活用されるようになると、プログラムが複雑化してゆきます。人間が決めた「ルール」を「仕様」として満たして動くプログラムが「正しく動くプログラム」と見なされるようになったからです。
「入力を処理して出力を返す」というのがプログラムの基本です。ある入力に対して、処理が介在して出力が決定する、という「モデル」でプログラムは動きます。あらゆる入力に対して想定される出力の組み合わせを網羅して「仕様」にできたとしたら、入力に対して正しい出力が得られるかどうか、つまり「バグがないこと」が確認できるはずです。
先ほどのキーボードを例に取ると、キーコードを入力となる「集合A」、文字コードを出力となる「集合B」とします。バグのないプログラムを作ることは、集合Aから集合Bを得る「写像」を作ることに他なりません。
現代数学では「数」は「集合」です。「計算」を数学的に言い換えると「関数」ですが、関数とは現代数学では「写像」のことです。ある数を関数に与えて結果の数を得ることは、集合を写像にかけて別の集合を得るということに他なりません。この「計算のモデル」は、形式的には「プログラムのモデル」と同じです。
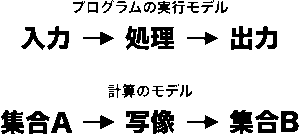
どうやればバグのないプログラムを作れるのかを研究した数学の分野があります。「型理論」や「ラムダ計算」、それを元にした「形式的証明可能性」がそれです。今書いた「入力の集合から出力の集合が得られる写像が完璧ならバグはないよね?」というのが理論の超訳なのですが、多くの型は「まあ確かにそうだな」と思うのではないでしょうか。
これらの理論から派生して誕生した「関数型言語」と呼ばれる種類のプログラミング言語があります。では、すべてのプログラムを関数型言語で作ればバグがなくなるか、というと実はそうではありません。先ほどの理論でバグがないことを保証するためには、プログラムを「純粋関数型」と呼ばれる形にする必要があります。純粋関数型にするには、「副作用の無いプログラム」を作る必要があるのです。
ここでいう「副作用」というのは、簡単に言うと「予期せぬ影響」のことです。キーボード制御の例で言うと、たとえばコーヒーをこぼして回路がショートを起こしたとします。入力として期待する集合と違う信号が送られてきたり、そもそも信号が送られてこないかもしれません。このような「副作用」が起こると、プログラムが正しく動く前提条件が崩れてしまいます。
画面への表示やデータベース処理、ネットワーク処理なども、同様に「副作用」の仲間です。外部システムで起こっていることは、純粋な「数学的写像」の中で確認することができないからです。
外部システムの制御に使うという「応用」こそが現代のコンピュータの便利さの本質だともいえます。でも、その便利な部分の多くは「副作用」として扱われてしまうのです。だとすると、「形式的証明可能性」が言おうとしていることは、バグのないことを完全に保証するためには、純粋な「計算」をしていた時代に逆戻りしなければならない、ということのようにも聞こえます。
現代のプログラミングにおいてバグの少ないプログラムを作るコツは、システムの要件を抽象的に分解して、純粋な計算で実行できる部分と、外部システムで起こりうる「例外」を切り分けることのような気がします。保険や金融、セキュリティなどの分野では、実際にそのような手法で致命的なバグのないプログラムが作られていて、関数型言語が活躍しています。このような分野では不具合が巨大な不利益を引き起こすことがあるため、コアとなるロジックだけを抜き出して純粋関数型として実装する、という開発手法がとられています。
「デバッグ」は不具合の原因になっていた「バグ(蛾)」を取り除いて直したことから命名された、という話があります。1940年代に開発、運用されていたリレー式プログラム計算機Mark IIのエラーを探っていたら、回路に潜り込んで回路をショートさせていた蛾が見付かったのです。正しく動く前提で設計されていた回路が変わってしまうわけですから、これも副作用によって引き起こされたバグの一つ、と言えるかもししれません。
私がプログラミングを始めた頃、これと似たようなバグを何度も経験しました。当時はCPUが実行する命令、いわゆる「マシン語」を直接読み書きすることでプログラムを作っていました。数値として書き込まれたプログラムをデータのように扱って書き換えながら実行する「自己書き換え」という手法があります。プログラムの高速化や省スペース化にとても効果があるテクニックだったので、私も応用したものです。
ただし、自己書き換えに失敗すると大変なことが起こります。BIOS(バイオス)と呼ばれるシステムを動かしているプログラム自体を書き換えてしまうという深刻な「副作用」が起こるのです。システムの根幹部分が壊れるわけですから、コンピュータはまともに動きません。動かなくなったシステムは再起動をすることになりますが、保存をしていないプログラムが消えてしまい、再実装することもしばしばでした。
今のコンピュータ上で動くプログラムは「ユーザーランド」と呼ばれる一種の「箱庭」の上で動きます。システムが書き込まれる部分とユーザーの作ったプログラムが動く部分が分かれていて、ユーザーが作ったプログラムが遊び戯れる場所からは容易に書き換えができないようになっているのです。
今から考えるとずいぶん野蛮な環境でプログラミングをしていたものです。でもそのおかげで、コンピュータのアーキテクチャについて深く学ぶことができたのだとも思います。
中学生当時の私は「PDCA」という言葉は知りませんでしたが、エラーからのリカバリーに時間がかかると成果物が完成するまでに時間がかかる、ということも肌身で学びました。定期的にチェックポイントを設けて修正途中のプログラムを保存したり、システムを壊すような深刻な副作用が起こる可能性のある部分をうまく切り分けたりしながら開発をする、という姿勢が身に付いたのはその時期でした。
マシン語というのは、CPUが理解し実行する命令を数値に置き換えた集合です。メモリに書き込まれている数値は、CPUが解釈すればマシン語の命令になりますし、プログラムで読み込めばデータになります。数値としての両者には本質的な差はありません。どのよう扱われるのか、という「解釈の差」があるだけです。
今のAIだって、人間のように「理解」をしているわけではないのです。世界の様々な「様子」や「状態」を数値化し、「変化」を数式に置き換えて「結果が同じになる」ということを応用しているにすぎません。プログラミングやAIを学ぶ上でとても重要なこの「感覚」を学べたのは、今から考えると劣悪な環境で学んで得た嬉しい副作用だったと思います。他にも、失敗によって学んだことは沢山あります。
数学者のチューリングは、計算手が仕事をする様子を見ながら、計算の手順そのものを「モデル化」する方法について考え始めたと言われています。その時、「決して間違えない計算」とは何かについて考え、チューリングマシンを産み出しました。
第二次世界大戦当時、彼が勤めていたブレッチリー・パークでチューリングは、ナチスドイツの産み出した難解なエニグマ暗号を確率計算で解く、という仕事をしていました。暗号を解読するまでにかかる時間はとても重要でした。速く解読することによって大西洋上のUボートの位置を特定し、北米から物資を運ぶ商船への攻撃を防ぐことができるからです。人間が犯す間違いをせず、正確に速く計算をこなす機械を作る、という切実な要求が当時のイギリスにはありました。
チューリングはヒューマンエラーという「失敗」を「越えるべき壁」として認知し、彼の計算理論を応用して作った「ボンベ」や「コロッサス」のような自動計算機を使ってついにエニグマ暗号を解読する方法を見つけました。チューリングの計算理論を受け継ぎ、ノイマンは間違いのない計算手順を実行する機械の実現を目指して、現在の「プログラム内蔵型コンピュータ」の原型を考案しました。
「技術の発展」が「壁を越える方法の発見」のイテレーションだとすると、個々の発見に先立って必ず「壁の認知」が存在するはずです。「壁を認知して越える」というのは、発達のフレームワークと言えるものです。
似たようなことは私たち個々人にも起こっています。プログラミングに関して言えば、バグは私たちの目の前に現れる「壁」です。この壁を認知し修正することで、私たちは「学習」し「成長」して行くのです。
今、私たちはプログラミングの歴史において重要な転換点に立っています。
かつてプログラミングで出会うのは主に「人為的なバグ」でした。AIを使ったプログラミングをしたことがある人は分かると思うのですが、AIはよくバグを産み出します。今、私たちはAIが産み出したバグを人間が修正する時代に生きています。
この「新しい種類のバグ」にはいくつかのパターンがあります。たとえば事前にAIに与えるコンテクストが不足していたり、間違っているために産み出されるタイプのバグがあります。このようなタイプのバグは、プログラムにコメントを追加したり、ドキュメンテーションを充実させたりすることでAIがデバッグしてくれることがあります。
一方、そのような手法で直らないバグもあります。データ構造やアルゴリズム、クラスの使い方をある程度把握していないと、AIがコードを生成するために必要なコンテキストを渡すことができません。このタイプのバグは、人間側の「前提条件となる知識」が不足していて、正しい設計ができないために引き起こされるバグと言えます。そんなときは、AIに前提条件を質問して人間側の知識を補間する必要があります。コンテクストの不足があまりにニッチな領域で起こる場合は、ネットで調べたりgithubでサンプルコードを読んだりすることがあります。
後者のような「なかなか直らないバグ」に遭遇したとき、私たちは自分自身の「知識の境界」に立っているのです。プログラムが期待通りに動くように「デバッグ」されると、自分の境界が少しだけ広がった気持ちがします。
もう一つ感じるのは、「境界に立つまでの時間」が短くなったことです。大規模言語モデルには「自己の能力の増幅器」としての機能があります。自分が既に知っていることは秒で達成してくれるので、あっという間に「知識の境界」に達するような感覚があります。
ネットが登場して「プログラムは書く以上に読む」ようになったのですが、AIの登場によってさらに読む量が増えてゆくはずです。プログラミング初心者は、まずコードを「読んで理解できる」ようになる必要があります。これが、プログラミングの分野でスタートラインに立つためのリテラシーになるのではないかと思っています。
そして、まず分野ごとに必要なリテラシーを身に付けて、LLMの出力を読んで理解し、自分の境界を認知し突破する、という学びのスタイルは、他の分野にも応用可能なのではないかと思います。AIの出力をそのまま「投げる」のではなく、きちんと咀嚼して理解し、先に進もうとする姿勢がとても重要です。
現代のプログラミングは、チューリングやノイマンがかつて夢見たような、純粋に数学的な世界とはかけ離れた場所にあります。純粋な数学としては表現しづらい、副作用がたっぷりの「ドメイン知識」を含む世界が、今を生きる我々が直面しているプログラミングの世界です。
LLMのような技術の登場は、今までプログラミングと縁の遠かった世界も巻き込んで、周辺のドメイン知識を増やしてゆくはずです。私たちはこれから、AIが広げる新しいドメインの世界を、AIと共に学んで行くのかも知れません。
[参考書籍]
・コンピューティング史: 人間はいかに情報を取り扱ってきたか
計算からインターネット、SNSまで地続きのコンピュータの歴史を分かりやすく解説した書籍。
・関数型ドメインモデリング
今回まったく触れなかった「型」の話を含めて、関数型プログラミングのエッセンスを学べる良書。