December 5, 2025
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
ChatGPT に代表される生成AIを「なんとかローカルで動かしたい」という欲望は、エンジニアなら一度は抱くものだと思う。
「クラウドに一切つながずに、自分のPCだけで完結するAIアシスタント」。響きだけなら最高だ。
しかし、いざやってみるとすぐに壁にぶつかる。
モデルはローカルで動いても、「知識」はローカルにないのである。
LLMは大量のテキストで事前学習されているとはいえ、「いま」「ここ」で必要な具体的な情報はだいたいWebにある。
こういったものは、事前学習済みLLMの「過去の記憶」ではなく、Web検索しないと出てこない。
つまり、「完全ローカルで動くAI」を作ろうとしても、結局どこかのタイミングで Web検索エンジンに頼らざるを得ない。
では素直に、LLMからクラウドの検索APIを叩けばよいか?
…となると、次の問題が出てくる。
最近は各社が検索APIや「AI向け検索サービス」を提供している。品質も良いし、簡単に使える。
だが、だいたい従量課金である。
ローカルLLMと組み合わせて「会話の裏側で毎回Web検索する」ような仕組みにすると、
LLMがそこそこ賢く振る舞えば振る舞うほど、検索APIの利用料金が青天井で増えていく。
ローカルでLLMを回しているのに、
水道の蛇口のように「検索API課金」がチョロチョロではなくドバドバ流れ続ける、という本末転倒な状態になる。
もうひとつ、見逃せないのが プライバシーの問題 だ。
普通にクラウドの検索エンジンを使えば、
「どんなキーワードで何をどれだけ調べたか」という履歴は、当然ながら相手側に残る。
個人であれ企業であれ、
といったものが、検索ログを見れば透けて見える。
せっかくLLM本体をローカルに閉じ込めて守っていても、検索履歴がダダ漏れでは意味がない。
「モデルもデータもローカル。検索クエリまでローカルで完結したい」
というのが、本気でプライバシーを考えるなら自然な発想になる。
そこで発想を変えた。
検索するたびにクラウドに聞きに行くのではなく、
「検索の元ネタ」そのものをあらかじめローカルに持ってくればいいのでは?
具体的には、次のような構成を考えた。
こうすると、
という状態が作れる。
もちろん、Webページを1枚1枚手で集めてベクトル化するわけにはいかない。
そこで、クラウド側にはそれなりのインフラを用意することになる。
今回の実験では、ざっくりと次のような構成にした。
アーキテクチャとしては、
といった、シンプルだがそこそこスループットの出るパイプラインを組んだ。
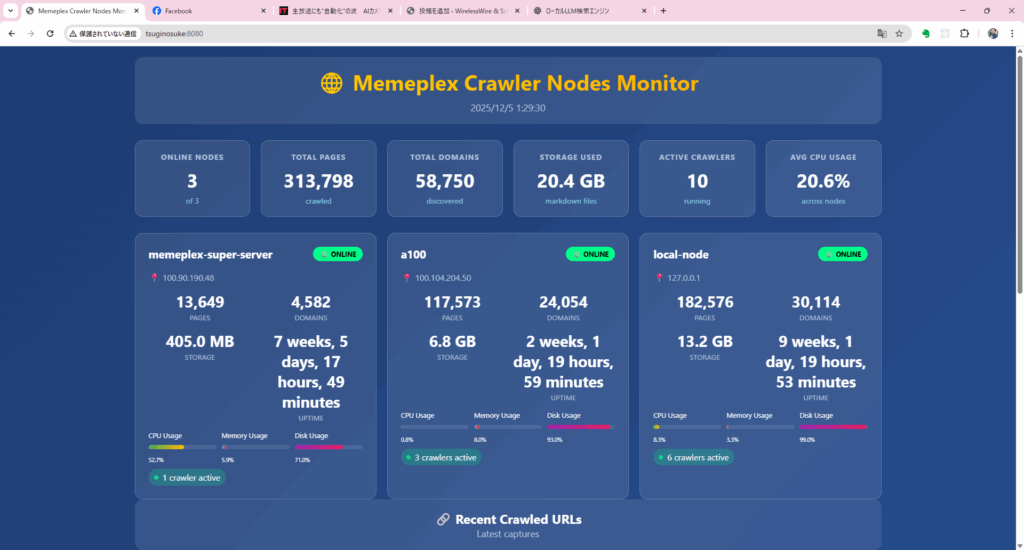
この構成でFreeAI社の持つAIスーパーコンピュータ継之助を中心に実験したところ、1日あたり約30万ページをインデックス することに成功した。もちろんWeb全体から見ればまだまだ一部だが、「個人用検索エンジン」にしては十分野心的な規模である。
クラウド側でインデックスされたベクトルDBは、定期的にスナップショットを取ってローカルに持ってくる。
サイズはそれなりに大きいが、最近のストレージ事情を考えれば、TB級までは現実的な範囲だ。
ローカル環境では、
という流れになる。
ここで重要なのは、
という点だ。
言い換えると、
「ある時点のWebの断面」を、自分のマシンの中にまるごとコピーしておいて、
それをLLMと一緒に使う——そんな感覚のシステムになっている。
実際には、まだまだ課題も多い。
など、真面目にやろうとすればするほど設計ポイントは増える。
それでも、「ローカルLLM×プライベート検索エンジン」という組み合わせは、
次のような意味で非常に面白い。
これまで、「検索」はクラウド側にあるのが当たり前だった。
だが、LLMがローカルで動くようになってきた今、
モデルだけでなく、検索インフラそのものを分割する
「クロール&インデックスはクラウド、検索と利用はローカル」
という形は、十分に検討に値する。
クラウドとローカルの役割をうまく分担させることで、
コスト・プライバシー・利便性のバランスを取り直すことができる。
今回、10ノード+GPUという構成で1日100万ページをインデックスする実験に成功したことで、
「個人でもここまでの規模感の“自前検索エンジン”を持てる」ことが見えてきた。
ローカルLLMを本気で育てたいなら、
次に必要なのは 「ローカル検索をどう作るか」 だ。
そのためのひとつのアプローチとして、
「プライベートWeb検索エンジン」を作ってみたのである。