January 14, 2026
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
再帰的言語モデル(RLM)は今最も注目を集めている大規模言語モデルエージェント・アルゴリズムである。
通常「モデル」という言葉が語尾につくと、それはAIそのものを指すことが多いが、「再帰的言語モデル」の場合、実際の「モデル」は、既存のOpenAIのChatGPTでも、ローカルで動作するgpt-ossでも、DeepSeekでもいい。では何が「再帰(Recursive)」なのかというと、LLMの「呼び出し方」である。これが各方面で次々と成果を発揮し、大変な注目を集めているのだ。
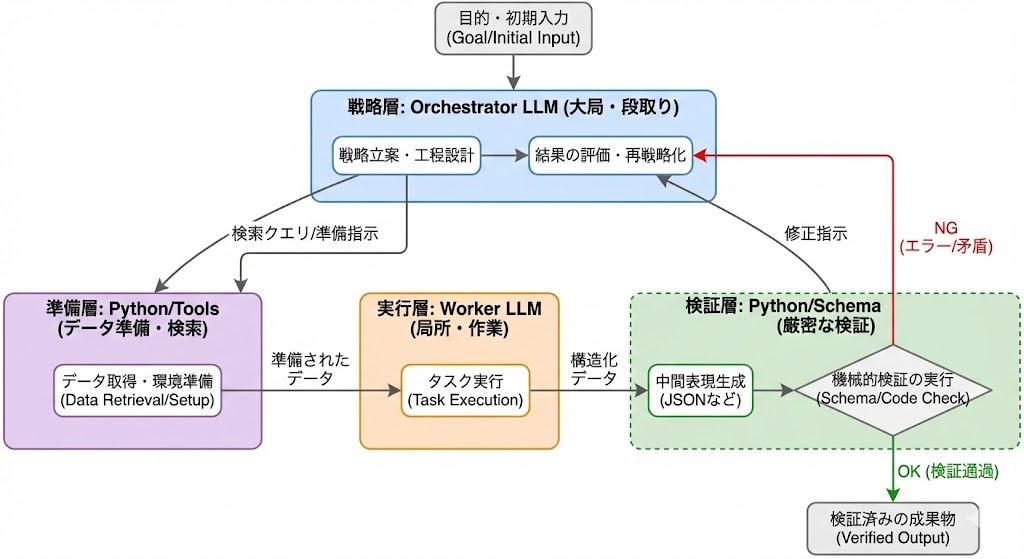
再帰的言語モデル(RLM)の本質は、「LLMを一発回答の生成器として使う」のではなく、複数の推論ステップを持つ手続き(procedure)として編成し、自己修正しながら目的の成果物へ収束させる点にある。ここで重要なのは“再帰”という言葉の響きよりも、実装上の設計原則だ。私はRLMを、少なくとも次の3要素の組み合わせとして理解している。オーケストレーター、ワーカー、そして中間コードだ。
第一に、オーケストレーターLLMとワーカーLLMの役割分担である。オーケストレーターは大局的な戦略を立てる。具体的には「どの資料を読むべきか」「抽出すべきスキーマは何か」「矛盾が出たらどの観点で再検証するか」「未知が残った場合に次の一手は何か」といった、工程設計と段取りを担う。一方で、ワーカーLLMは局所的な作業を担当する。たとえば「この段落から顧客要望を候補抽出する」「この候補の根拠となる引用箇所を特定する」「このフィールドの欠落理由を分類する」といった、粒度の小さいタスクを大量に捌く。
LLMの中身そのものはローカルのものでも良い。gpt-ossはその意味では非常によく働く。オーケストレーターとワーカーは役割が違うだけで同じLLMで良い。
この分業が効く理由は、LLMの失敗が往々にして「大局と細部の混線」で起きるからだ。戦略を考えながら同時に細部を埋めると、モデルは“もっともらしい整合”を優先してしまい、検証が甘くなる。戦略と実務を分けることで、作業の責務が明確になり、失敗の検知と修正がしやすくなる。
第二に、Pythonコードなどの“非自然言語的な中間表現”を挟む点である。RLMが単なる「プロンプトの工夫」と違うのは、言語だけで全てを完結させず、途中に機械的に検査可能な表現を置くことにある。たとえば抽出結果をJSONにし、Pythonでスキーマ検証を行う。重複や欠落、型不一致、相互参照の矛盾をコードで弾く。あるいは、候補の根拠引用が本当に原文に存在するかを文字列一致や範囲照合で検証する。
これは「モデルが賢くなった」から精度が上がるのではない。LLMが苦手な“厳密さ”を、コードと型と制約で肩代わりし、LLMには“意味の解釈”を担当させるから精度が上がる。言い換えるなら、RLMはLLMを“推論エンジン”として使いつつ、検証と制約は“計算機の得意技”に寄せるアーキテクチャだ。
第三に、検証→差分修正→再実行のループを回すことである。RLMでは、最初の抽出はあくまで暫定解にすぎない。Pythonで検査してエラーが出たら、そのエラー(欠落フィールド、矛盾、根拠不足など)を「次の入力条件」としてオーケストレーターに返し、再度ワーカーにタスクを割り当てる。重要なのは、やり直しを“精神論”ではなく、プロトコルとして設計することだ。
例えば「フィールドが埋まらない場合は“未確定”を許す」「未確定のまま残した理由(情報が本文にない/曖昧/複数候補)を分類して残す」「矛盾が出たら根拠引用を必須にして再抽出する」といったルールを先に決める。こうすると、モデルが勢いで“それっぽい完成品”を捏造する余地が減り、システム全体として信頼性が上がる。
この三つをまとめると、RLMとは、LLMを中心に置きながらも、実際には**(1)戦略立案担当(オーケストレーター)と(2)局所作業担当(ワーカー)に分解し、さらに(3)Python等で検証可能な中間表現を挟み、(4)誤りを差分として回収し再帰ループで収束させる方式だと言える。
従来の「LLMに抽出させて人間が目視で直す」運用がスケールしなかったのは、失敗が最後に露呈し、修正が属人的だったからだ。RLMは失敗を途中で機械的に検出し、修正を自動で次工程に流す。これが、“非構造化→構造化”のような業務で予想以上に効いてくる。
RLMのコアは、賢い一発回答ではなく、検証可能な中間表現と再実行プロトコルによって“正しさへ収束する工程”を作ることにある。
筆者が開発している「KnowledgeSTATION」にRLMによる非構造化データから構造化されたデータを取り出す機能をつけたところ、予想外にうまくいって驚いた。
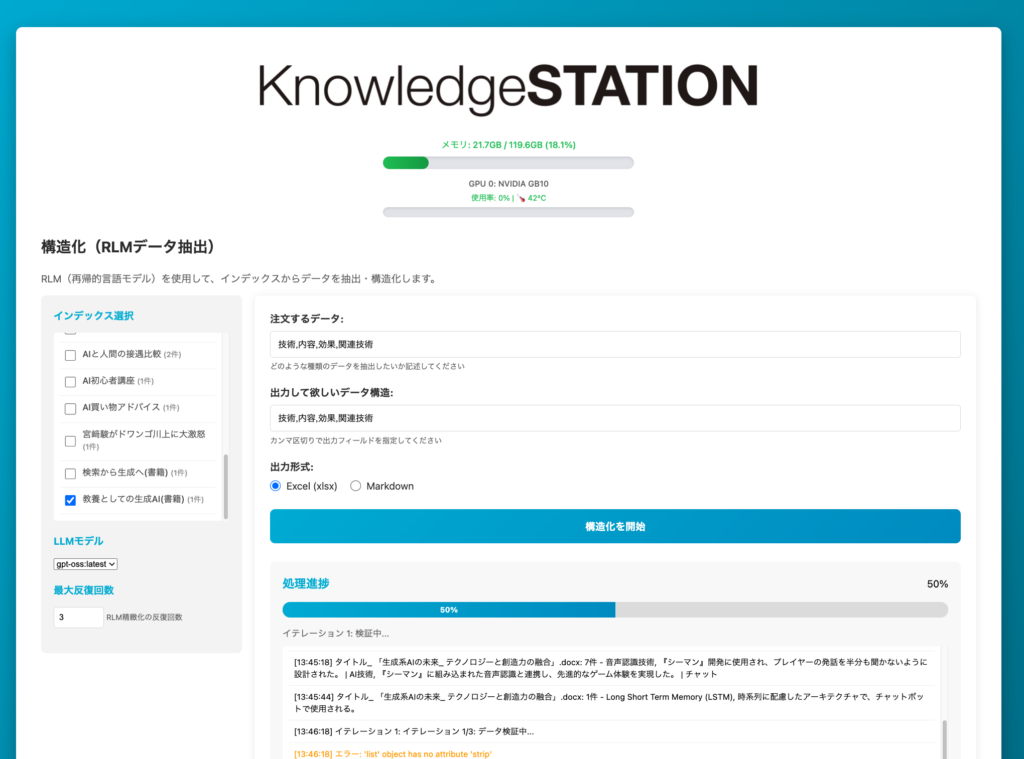
例えば、過去の著作や議事録、講義録など雑多な情報を貯めた知識ベースに、「注目するデータ」と「出力して欲しいデータ」を渡す。例えば「技術的な話題」に注目し、「技術,発明者,その効果,関連する技術」が欲しいと指定すると、自動的にデータを検索して構造化してくれる。
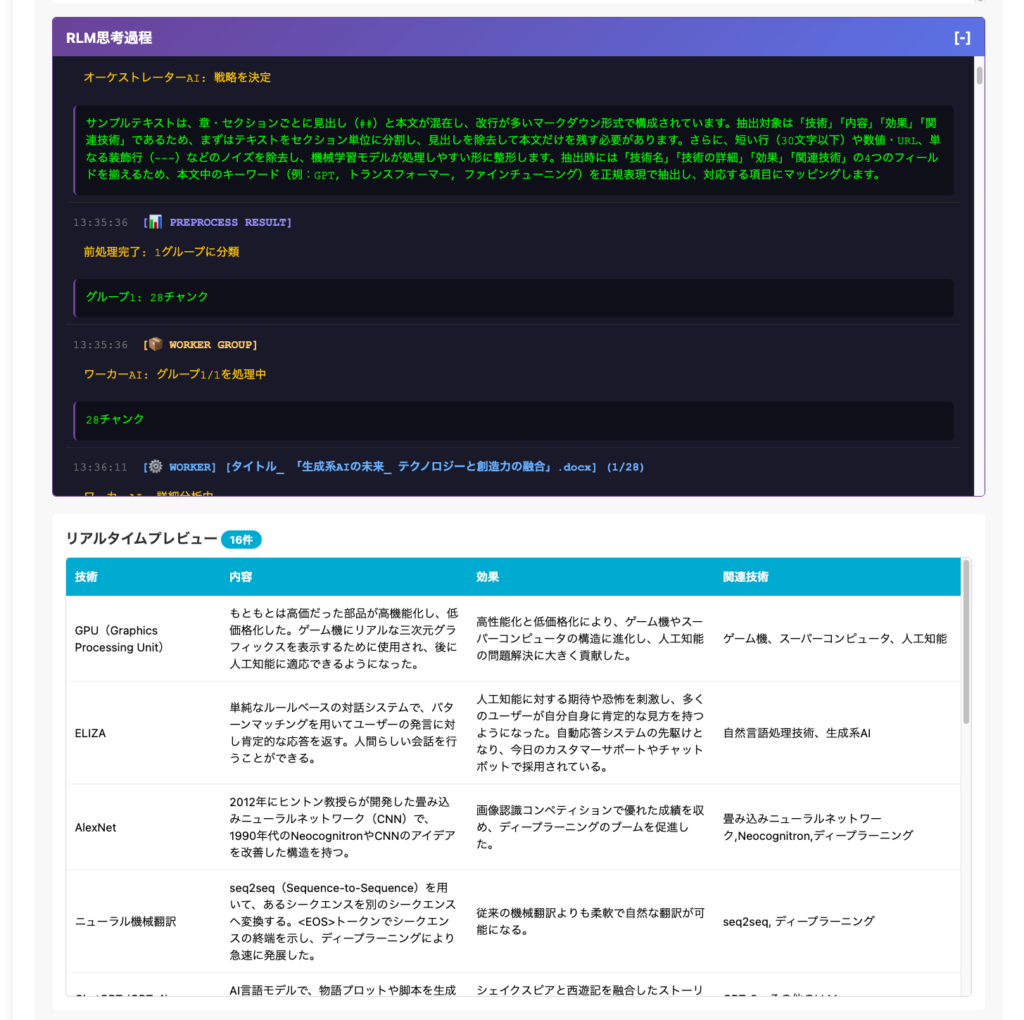
実際にRLMがどのように動作して情報をかき集め、まとめているのかという過程も可視化されているため、もしも間違ったデータが出てきたとしてもどこで間違ったのか理解しやすいというメリットもある。
実際に筆者の過去の著作から抽出された技術に関する構造化データは以下のようになる。
| 技術 | 内容 | 効果 | 関連技術 |
|---|---|---|---|
| GPU(Graphics Processing Unit) | もともとは高価だった部品が高機能化し、低価格化した。ゲーム機にリアルな三次元グラフィックスを表示するために使用され、後に人工知能に適応できるようになった。 | 高性能化と低価格化により、ゲーム機やスーパーコンピュータの構造に進化し、人工知能の問題解決に大きく貢献した。 | ゲーム機、スーパーコンピュータ、人工知能 |
| ELIZA | 単純なルールベースの対話システムで、パターンマッチングを用いてユーザーの発言に対し肯定的な応答を返す。人間らしい会話を行うことができる。 | 人工知能に対する期待や恐怖を刺激し、多くのユーザーが自分自身に肯定的な見方を持つようになった。自動応答システムの先駆けとなり、今日のカスタマーサポートやチャットボットで採用されている。 | 自然言語処理技術、生成系AI |
| AlexNet | 2012年にヒントン教授らが開発した畳み込みニューラルネットワーク(CNN)で、1990年代のNeocognitronやCNNのアイデアを改善した構造を持つ。 | 画像認識コンペティションで優れた成績を収め、ディープラーニングのブームを促進した。 | 畳み込みニューラルネットワーク,Neocognitron,ディープラーニング |
| ニューラル機械翻訳 | seq2seq(Sequence-to-Sequence)を用いて、あるシークエンスを別のシークエンスへ変換する。<EOS>トークンでシークエンスの終端を示し、ディープラーニングにより急速に発展した。 | 従来の機械翻訳よりも柔軟で自然な翻訳が可能になる。 | seq2seq, ディープラーニング |
| ChatGPT (GPT-4) | AI言語モデルで、物語プロットや脚本を生成できる。 | シェイクスピアと西遊記を融合したストーリーを一貫性を持って作成できる。 | GPT-3、その他のLLM |
| トークン上限 8000 | ChatGPTが1回の入力で処理できる最大トークン数。 | 長文や詳細なストーリーを一度に生成できる。 | トークン化、GPT-3の4096トークン上限 |
| プロンプトエンジニアリング | モデルに望む出力を指示するためのプロンプト設計。 | 出力の関連性と具体性を高める。 | ファインチューニング、インストラクションチューニング |
| 英語で書くことでトークン節約 | 日本語より英語の方が1単語あたりのトークン数が少ない。 | トークン枠を有効活用し、より多くの内容を含められる。 | 言語別トークン化の違い |
| 音声認識技術 | 『シーマン』開発に使用され、プレイヤーの発話を半分も聞かないように設計された。 | プレイヤーに無愛想で気まぐれなキャラクターとして錯覚させ、ゲームの独特な世界観を演出した。 | AI技術, チャットボット |
| AI技術 | 『シーマン』に組み込まれた音声認識と連携し、先進的なゲーム体験を実現した。 | ユーザーに愛され続編・リメイクへとつながる人気を生み出した。 | 音声認識技術, チャットボット |
| チャットボット | ELIZAの構造を踏襲し、人間の錯覚を利用した会話を実現するシステム。 | ユーザーが実際に存在する生き物と錯覚するように仕向け、会話体験を向上させた。 | ELIZA, AIML, seq2seq, ディープラーニング |
| ELIZA | 1960年代に開発された会話型プログラムで、パターンマッチングと応答生成を行う。 | ユーザーに知性を持つ存在と錯覚させる効果があった。 | チャットボット |
| AIML | Artificial Intelligence Markup Languageで、パターンマッチングを用いて応答を生成する。 | 簡易的なチャットボットや会話システムの開発に利用できるが、品質はスクリプト量に比例する。 | チャットボット, パターンマッチング |
| seq2seq | エンコーダーとデコーダーから構成され、対話履歴をベクトル化して自然言語応答を生成する手法。 | 文脈を考慮し、自然に聞こえる回答を生成できるため、従来より自然な対話を実現した。 | ディープラーニング, Google, Twitterデータ |
| ディープラーニング | チャットボットにブレークスルーをもたらし、seq2seqなどのモデルで対話生成を可能にした。 | ユーザーサポート等で活用され、チャットボット開発環境の整備を促進した。 | seq2seq, AIML, チャットボット |
| Long Short Term Memory (LSTM) | 時系列に配慮したアーキテクチャで、チャットボットで使用される。 | 統計的・確率的に受け答えを選ぶため、時間的依存性を考慮した応答が可能になるが、実際には「それっぽい」回答を選んでいるだけ。 | チャットボット,大規模言語モデル |
途中「トークン上限 8000」など、純粋に技術そのものとは言えないものも出てくるが、索引などに引用する場合はこういうまとめ方もあり得るかと納得できなくはない。
構造化されたデータはExcel形式でダウンロードできるようにした。
面白いのは、RLMがうまく回り始めると、非構造化データの“ノイズ”が、むしろ追加情報源になる点である。議事録の脱線、雑談、言い淀み、感情的な言葉――従来は邪魔者扱いだった要素が、「優先度の根拠」や「リスクシグナル」として意味を持つ。たとえば「それ、今日中にやらないとまずい」という一言が、期限の強制力を示す。顧客が同じ要望を三度言うなら、それは単なる繰り返しではなく“強い痛み”の表現だ。RLMは再帰の過程で、こうした文脈特徴を拾い上げ、構造化スキーマに落とし込める。
もちろん課題もある。第一に、再帰は計算コストを増やす。ループを回すほどトークンも増え、遅延も増える。第二に、再帰の品質は、検証関数(何を矛盾とみなすか、根拠は十分か、スキーマ制約を満たすか)の設計に依存する。第三に、ドメインによっては「そもそも根拠がテキストに存在しない」ことがある。会議で決まったはずなのに議事録に書かれていない、などだ。その場合は、未確定を無理に埋めず、追加の情報取得フロー(関係者への確認、関連スレッドの探索)に接続する必要がある。エージェントとは、万能の魔法使いではなく、情報の欠落を検知して次の行動へつなげる“工程管理”でもある。
それでも、方向性としては明確だ。今後、LLM活用の主戦場は「文章生成」ではなく、「非構造化データを、意思決定可能な構造へ変換する」ことになる。人間の組織が抱えるボトルネックは、情報の不足ではなく、情報の“形式”だ。見つけられない、比較できない、集計できない、追跡できない。RLMは、ここに正面から切り込むための基本部品になり得るだろう。
また、完全にローカルで動作するという点も見逃せない。
クラウドAIのAPI利用料金や制限に悩まされることなく黙々とデータを構造化していく様は見ていてワクワする。
RLMによってエージェンティックAIは新しい局面に到達できるかもしれない。