日立製作所 研究開発グループ Digital Innovation R&D デジタルインフライノベーションセンタ データ&ナレッジマネジメント研究部 主任研究員・西川 記史(左)/研究員・高尾 大樹(右)
Transitioning from Static to Dynamic Pruning Architectures
June 17, 2026
日立製作所「協創の森」の現場から hitachi_editor
日立製作所・研究開発グループのメンバーが研究開発中の技術について語ります。
グラフ構造、すなわちノード(グラフの頂点)とエッジ(頂点同士を結ぶ辺)を用いてデータを表現する構造のデータベース(グラフデータベース)に対する再帰問い合わせは、複雑な関係を正確にたどれる一方、探索範囲が広がりやすく処理時間が増大しやすいという課題を抱えてきた。そこで日立製作所 研究開発グループは、東京大学と共同で、従来の「広く読んで後で絞る」方式に対し、「不要な領域は読み込まない(プルーニングする)」という発想に転換する新技術「動的プルーニング技術」を開発した。データベースなどへの検索要求(クエリ)実行中に探索範囲を動的に絞り込むことで、製造業やヘルスケア分野などで実用的な応答性能を実現する。データ&ナレッジマネジメント研究部の西川記史主任研究員と高尾大樹研究員に、開発の経緯から今後の応用までの取り組みを聞いた。
(本記事は、日立製作所・研究開発グループ「研究の現場から」の抄録です。全文はこちら)
西川:動的プルーニング技術の開発のきっかけは、データベースを産業分野で活用できないかと考えていた頃に遡ります。グラフ構造データは、ノードとそれらを結ぶエッジによりネットワーク状になった、相互に複雑なつながりを持つデータ構造です。こうした構造のデータを管理するデータベースが「グラフデータベース」ですが、すでに産業界における分析業務では活用されていました。ところがこのグラフデータベースには、データ量が増加したりデータの階層が深くなると「検索が遅くなる」という致命的な弱点があったのです。ですからもっとグラフデータベースを活用していただくには、この「検索の遅さ」に対処する必要があり、そのための研究を本格化させた、というわけです。
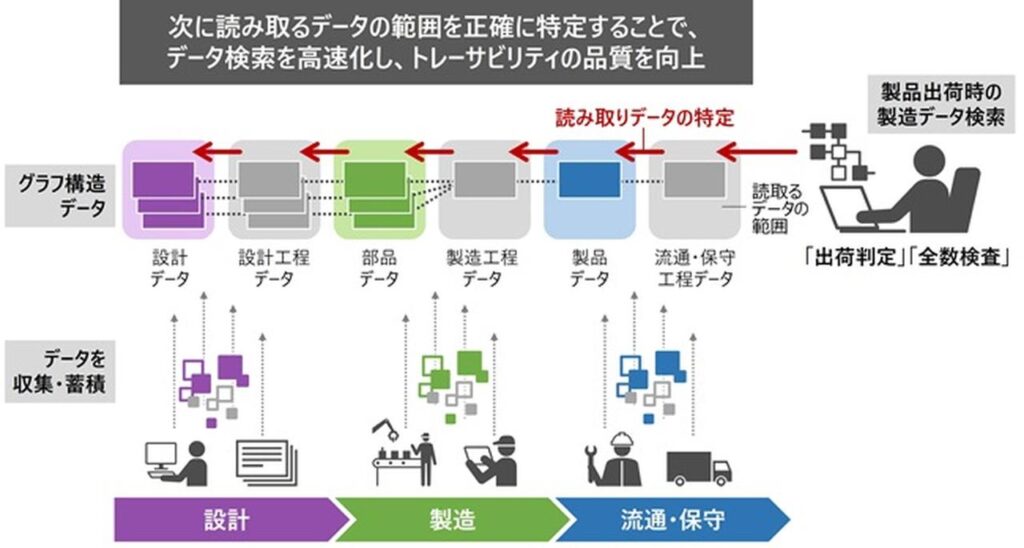
研究を本格化するにあたり、私たちは「再帰問い合わせ」に着目しました。再帰問い合わせとは、ある検索結果を次の検索条件として使い、関係をたどりながら繰り返し問い合わせを行うことで、再帰クエリとも言います。例えば製造業におけるグラフデータベースの活用例として、部品のトレーサビリティ(追跡可能性)があります。ある製品に対して、どのような部品がどのような順番で使われているかをトレース(追跡)するとき、製品から部品へと製造時の逆順にたどっていく必要があるわけです。そしてここで再帰問い合わせが使われます。製品には多くの部品が使われていますから、グラフ構造を再帰問い合わせでたどっていくために多くの時間を必要とするのはご理解いただけると思います。

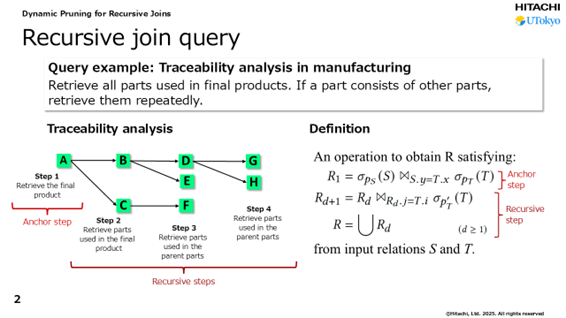
高尾:トレーサビリティにおいて、ある製品を構成している部品すべてを探す例で、グラフデータベースに対する再帰問い合わせについて考えてみましょう。最終製品「A」について、構成する部品を検索していくプロセスです。製品Aを構成する部品「B」「C」を検索し、さらに「B」を構成する「D」「E」を探し出し、「D」の構成部品である「G」「H」を見つけます。一方、部品「C」についても、構成部品の「F」を探し出します。再帰問い合わせでは、すべての部品の検索にグラフデータベース上の不要な領域も含めて広く探索してしまいます。「B」を見つけるときも、「G」や「H」を見つけるときも、ほぼすべての広い領域で経路を検索するため、時間がかかるのです。
解決策として静的プルーニング(Static Pruning)という技術がありました。問い合わせのコンパイル(問い合わせ文を解析し、データベースが実行できる内部形式に変換する)時にフィルターベースでサマリー情報をあらかじめ用意することで領域を狭める方法です。ある製品の部品を検索するときは、値の範囲がここからここまでを検索すれば良いということを上位のステップに伝えて、検索の幅を狭めます。事前にクエリを最適化することで、検索時間を短縮できます。ただし、その静的プルーニングも、最初のうちは効果的に検索できるのですが、再帰問い合わせの段数が深くなると読む範囲が増えて時間がかかるようになる弱点がありました。
西川:商用データベースのHADBですでに動的プルーニング技術は稼働しています。導入すればすぐにご利用いただける状態になっています。これまでに製造系のお客さまでうまく使っていただいていますし、ヘルスケア分野での適用も進んでいます。今後有力なのは電力(送電)やAIなどの分野でしょうね。ここで動的プルーニングは大いに威力を発揮するはずです。
この技術は、東大との共同開発に加え、内閣府の国家プロジェクトである戦略的イノベーション創造プログラム(SIP)の第3期の課題としても研究開発を進めています。このプログラムの「統合型ヘルスケアシステムの構築」には15プロジェクトがあり、私たちはその中の「大容量医療データの高速処理・高効率管理・高次解析基盤の開発」(研究開発責任者:合田 和生 東京大学 生産技術研究所 教授)に取り組んでいます。狙いは「医療デジタルツインの構築」で、高速解析技術として動的プルーニング技術を適用する研究を進めています。
高尾:私自身は、動的プルーニング技術から離れた研究テーマに現在は主軸を移しています。生成AIの利用が広がる中で、非構造データを取り扱うことが増えているのはみなさんご承知の通りかと思いますが、一方で非構造データはRDBで扱うことが難しいという課題がありました。私は非構造データを高次元ベクトルに変換して管理することで、RDBの枠組みの中で取り扱えるようにする技術開発に取り組んでいます。このベクトルデータベースは、2026年春に学会で発表しました。
参考:日立と東大、ビッグデータ検索を最大135倍高速化する「動的プルーニング技術」を開発
