May 28, 2026
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
「これを一年間も作っていたの?お客さんもいないのに?」
「はい」
一瞬で嫌な空気が流れた。
おしゃれなカフェスペースにぎゅうぎゅう詰めに詰め込まれた社員たちを前に、この会社の共同創業者である筆者は、最新の研究開発事例を聞いていた。
「一年間もお客さんが見つからないようなもの、開発続ける意味ある?それは本当に必要とされてるわけじゃないってことじゃないか」
「僕は製造業出身です。製造業の現場では、このアプリが本当に必要なんです」
「でも売れてないんでしょう?ただの一本も」
「それは・・・」
「あと少し待つとして、売れなければこのプロジェクトは廃止すべきだ。撤退基準を決めて、厳粛に運営しろ」
断っておくが、筆者は社員が苦心して進行しているプロジェクトを明示的に中止しろと言ったことは20年の経営人生で一度しかない。これが2度目だった。
もっとも、すでにこの会社の経営から身を引き、共同創業者の一人で顧問という強制力のない立場に過ぎない。ただ普通の感想として、お客さんが一年も付かない商品を作り続けるというのは、少なくとも売上十億円規模の零細ソフトウェア企業がやることではない。
それから六ヶ月が経過した。
生成AIブームが始まってから、もう何度も聞かされた言葉がある。
「社内文書をRAGで検索できるようにしました」
「議事録をAIで要約できるようにしました」
「チャットボットでナレッジ共有します」
なるほど。便利ではある。
しかし、筆者はずっと、そこにある種の物足りなさを感じていた。
なぜなら、RAGやLLMをいくら高度にしても、肝心の“ナレッジ”そのものが痩せていれば、出てくる答えも痩せているからだ。これは当たり前の話で、冷蔵庫に残り物しか入っていないのに、ミシュラン三つ星のシェフを呼んでも、まあ限界はある。漁村でとれたての食材を主婦が調理した方が美味い。
AIの性能が上がれば上がるほど、実は逆説的に問われるのは、AIそのものではない。
「人間の知的生産物を、どのような形で蓄積しているか。それは即座に再利用できる形になっているか」
この問題は、特に製造業で深刻だ。製造業には、ものすごい量の知見がある。しかもそれは、単なる文章ではない。
CADデータ、CAE解析結果、試験結果、設計変更の履歴、過去のトラブル、レビューでの議論。
そして何より、熟練エンジニアの頭の中にしか存在しない「なぜこの形にしたのか」という設計意図。
この「なぜ」が失われると、ノウハウは急速に形骸化した置物になる。
図面は残っている。3Dモデルも残っている。解析結果のファイルも残っている。でも、なぜそうしたのかがわからない。
すると、後任のエンジニアは過去の設計を信用できない。
信用できないから、また一から解析する。また試作する。またレビューする。そして同じ失敗を、別の部署で、別のプロジェクトで、もう一度やる。
これは実に人類らしい。人類はだいたい、同じ失敗を何度もやる。
会社組織になると、それが少し高価になるだけだ。
近年、製造業では「デジタルスレッド」という言葉がよく使われる。
設計、解析、試験、製造、検査といった製品ライフサイクル全体を、デジタルデータでつなぐ。
最新のオリジナルデータを、各フェーズで参照できるようにする。そこが肝心なところだ。
しかし、デジタルスレッドは基本的には「データの通路」である。
通路ができれば、人や物は移動できる。だが、通路があるだけでは、そこで起きた会話や判断や迷いまでは残らない。
実際の設計現場で価値があるのは、最終的に採用された形状だけではない。不採用になった案にも価値がある。
なぜその案はダメだったのか。どの条件では成立し、どの条件では破綻したのか。過去に似た形状でどんな問題が起きたのか。CAEではどの境界条件を置き、何を観察し、何を疑ったのか。そういうプロセスの中に、設計知は宿る。
ところが従来のPDMやファイルサーバーでは、そこまでうまく扱えない。PDMは成果物の管理には強い。
しかし、検討過程や設計意図や解析の読み解きのような、半分構造化され、半分人間の解釈に依存する知識を扱うのは苦手だ。
まあそんな現実が、製造業の現場にはあるらしい。
筆者はちょうど40歳になった頃、人生の折り返し点で製造業のノウハウを持つソニーCSLとAIの社会実装を行うジョイントベンチャーを設立した。それがギリア株式会社である。ギリア(GHELIA)という名前とロゴマークは、PlayStationやVAIOのデザインやネーミングを手がけた後藤禎祐が担当した。
冒頭で説明したように、筆者自身は今は経営から引退し、一株主と顧問の立場である。
冒頭の会議で数年ぶりにこの会社を訪れて開発中のこの製品を見せられた時は、「着想は面白いが、はたして本当にこれを必要とする現場は本当にあるのか?」と感じた。特にUIがひどい。専門家ならともかく、自分がこれを使って何か意味のあることができるようになるとは思えなかった。
「こんなものは全然ダメだ。お客さんもいないものを作るのにグズグズと時間をかけてはいけない。売れないソフトの開発を継続する必要性がわからない」
「僕は製造業出身です。製造の現場では、本当にこういう製品が必要なんです」
現場の社員は食い下がった。僕より年長の社員だった。
「なら、ちゃんとこのツールのお客さんを見つけてお客さんの役に立てるということを証明して見てせくれ」
ギリアは良くも悪くも大企業とベンチャーのちょうど中間くらいの温度感の会社だ。大企業からの出向組もいる。技術者は尊敬され大切に扱われている。普段、自分たちの仕事を否定されることはあまりない。後で聞いたが、彼らはショックを受け、その日の夜から会議を開いたそうだ。どうすればこの製品の有用性を説明し、顧客を獲得し、プロジェクトを継続することができるようになるか。
それからどうなったのか、数ヶ月の時を経て、彼らはキッチリと顧客を見つけ、製品を極めて完成度の高いものに仕上げた。
それが、GHELIA AutoDeckである。
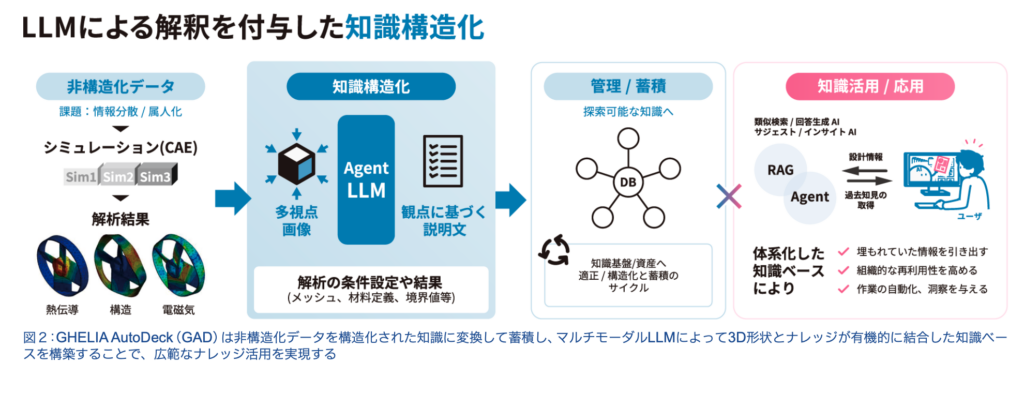
GHELIA AutoDeck、略してGAD(ギャド)は、CAD/CAEデータをナレッジとして活用するための基盤である。
ここで面白いのは、LLMの使い方だ。
一般的な生成AIの使い方では、LLMはユーザーの質問に答えるために使われる。
つまり、検索された文書を読んで、もっともらしい回答を返す。
しかしGADでは、LLMはその前段階で使われる。CADデータやCAE解析結果、シミュレーション画像、解析条件、境界条件、ログなどを読み解き、それらを構造化されたナレッジに変換して保存するのである。つまり、LLMを「答えるAI」として使うのではなく、まず「知識を作るAI」として使う。これはかなり重要な発想の転換である。
RAGの失敗の多くは、検索や生成の問題ではない。そもそも検索対象になっているナレッジが、AIにとっても人間にとっても扱いにくい形で散らばっていることが問題なのだ。
設計者が残したPDF。解析担当者が保存した画像。試験担当者が書いたExcel。レビュー会議の議事録。ファイル名だけでは意味のわからないCADデータ。
「最新版_final_修正2_本当の最終.step」みたいな、人の業を煮詰めたようなファイル名。
これらをそのままRAGに突っ込んでも、ロクなことにはならない。
GADのアプローチは、まずナレッジそのものを整える。CAE解析結果であれば、単に「画像を保存する」のではなく、その画像が何を意味するのかを説明する。応力集中がどこにあるのか。共振の可能性はどこにあるのか。設計諸元に対する余裕度はどうか。次に何を確認すべきか。
このような情報を、「目的」「観察事実」「議論・考察」「結論」「次のアクション」といった形で構造化していく。
これは、ただの要約ではない。設計行為の文脈を、機械が再利用可能な形に変換しているのである。
製造業の現場でよく起きる問題がある。
「あの解析、前任者しかわからないんだよね」
「あの部品、昔なにか問題があったらしいんだけど、詳細が見つからない」
「似たようなCADはあるはずなんだけど、検索に出てこない」
「過去トラブルを避けたいが、最終モデルしか残っていない」
こういう話は、だいたいどこの会社にもある。
熟練者は、多くの場合、説明しない。いや、正確には説明する時間がない。
本当は説明できる。
なぜこのメッシュにしたのか。なぜこの境界条件にしたのか。なぜこの形状はダメで、こちらの形状なら許容できるのか。そうした判断には経験と知識が詰まっている。それが技術者の魂の根幹にあるからだ。
しかし、それを毎回ドキュメント化するのは面倒だ。というより、現実的には無理だ。そんな時間はない。
ここに「ナレッジ蓄積のジレンマ」がある。
ナレッジを残すには、熟練者の時間が必要だ。しかし熟練者ほど忙しい。忙しいからナレッジが残らない。
ナレッジが残らないから、また熟練者に聞く。そして熟練者はさらに忙しくなる。
これは組織にとって、かなり深刻な知能的負債である。
GADはこの負債に対して、かなり正面から向き合っている。熟練者に「ちゃんとドキュメントを書いてください」とお願いするのではなく、日々の成果物そのものからナレッジを生成する。CADやCAEという、もともと業務の中で生まれるデータを起点にして、AIが説明文を生成し、構造化し、ナレッジDBに登録する。
これなら、ナレッジ蓄積は特別な作業ではなくなる。
設計行為の副産物として、知識が残る。
AIを戦力化し、効率的なナレッジの再利用が可能になる。
実際、筆者が最初に見て「主にUIがぜんぜんだめだ」と思った試作段階においても、GADはかなり高度な分析と考察をCAD/CAEデータを分析することに成功していた。これは製造業出身のエンジニアがチューニングしたからこそ実現できた技術であることは一目瞭然である。
もうひとつ重要なのは、GADが文章だけではなく、3D形状を扱う点である。
製造業の知識は、文章だけでは表現できない。形状そのものに意味がある。
似たようなリブ構造。
似たような応力集中。
似たような肉厚。
似たような部品配置。
似たような冷却経路。
似たような振動モード。
人間の熟練エンジニアは、形状を見れば「ああ、これは昔あの部品でやったやつに近い」と気づく。
しかし通常の検索システムは、形を見てくれない。
ファイル名や品番やタグに頼るしかない。
だから、「似たCADデータを探したい」という、現場では極めて自然な要求が、システム上は意外なほど難しい。
GADでは3D形状データをベクトル化して保存することで、形状の類似性に基づいた検索を可能にする。
これは、文章検索とは別種の価値を持つ。
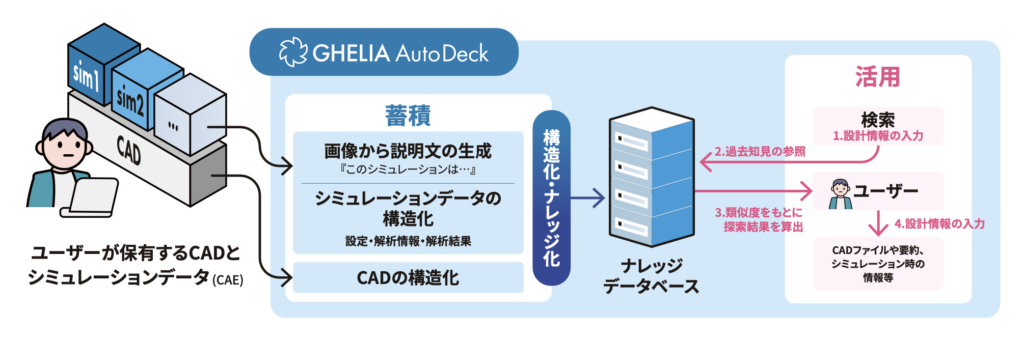
たとえば、ある新規部品を設計するときに、過去の似た形状を探す。
その形状に対して過去にどんなCAEを行ったかを見る。どんなトラブルがあったかを見る。どの設計案が不採用になったかを見る。なぜ不採用になったかを見る。そうすれば、設計者は最初から少し賢い状態でスタートできる。
組織としての学習能力が上がるということだ。
資料に出てくるユースケースでわかりやすいのは、V字開発における設計リードタイム短縮である。
製品企画から要求仕様が降りてくる。システムごとに性能目標が割り振られる。部品ごとに設計が行われる。仮想試験、試作試験を経て、最終的に出図に至る。
このプロセスの中で、過去の優れた形状や解析結果を再利用できれば、新規開発に集中できる。すでに素性が良く、検証済みの部品であれば、そこに過剰な工数をかける必要はない。逆に、本当に新規性があり、リスクのある部品にエンジニアリング資源を集中できる。
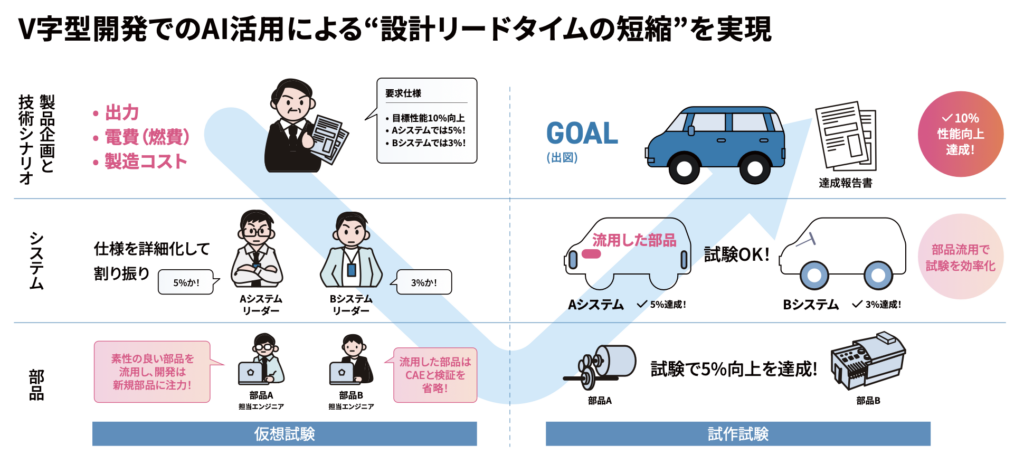
これは非常に現実的なAI活用である。
AIがいきなり自動車を設計する、という話ではなく、AIが人間の代わりに全てを判断する、という話でもない。
過去の知見を見つけやすくし、再利用しやすくし、判断の根拠を明確にし、その結果として、設計リードタイムを短縮する。
AIの導入でよくある失敗は、最初から「魔法」を期待することだ。しかし、現場で本当に価値を出すAIは、たいてい魔法ではない。人間がすでにやっているが、面倒で、時間がかかり、属人化している作業を、いい感じに機械へ移す。
GADが狙っているのは、まさにそこだ。
そしてこれは、製造の現場を知り尽くしたエンジニアが本気でAIと向き合うギリアだからこそ実現できた製品である。
これまで企業の競争力は、人材、設備、資金、ブランド、サプライチェーンなどで語られてきた。
もちろんそれらは今でも重要だ。
しかし生成AI時代には、もうひとつ重要な資産が前面に出てくる。
それが「知識資本」である。
企業が何を知っているか。どのような失敗を経験しているか。どのような設計判断をしてきたか。どのような暗黙知を持っているか。それらをどれだけ再利用可能な形で持っているか。
AIは、知識資本を増幅する装置である。もちろん、増幅する対象がなければ意味がない。
ギターアンプに何も入力しなければ、ただノイズが鳴るだけだ。LLMも同じである。企業の知識資本が整っていなければ、AIはそれっぽいノイズを出すだけになる。
だから、これからのAI導入で重要なのは、単に「どのモデルを使うか」ではない。
GPTなのかClaudeなのかGeminiなのか、という話ももちろんある。モデルは放っておいても勝手に進化する。その時一番性能が良いモデルを使えば良い。最近はローカルLLMも相当レベルが上がっている。
しかし、それ以前に、自社の知識を先に構造化しておかなければ、AIと無関係に企業の競争力は急速に減衰する。
製造業において、その知識は3D形状と深く結びついている。設計意図、解析結果、試験評価、製造性、検査結果。それらは単独ではなく、互いに関係しながら意味を持つ。
GADは、この関係性そのものをナレッジとして扱おうとしている。
もうひとつ、見逃せない点がある。GADは企業固有データの秘匿性を重視し、オンプレミス環境での稼働を想定している。これは製造業ではかなり重要だ。
CADデータやCAE結果は、企業にとって極めて機密性が高い。そこには製品の競争力そのものが含まれている。簡単に外部クラウドへ投げられるものではない。
もちろん、クラウドAIは便利だ。僕も毎日のように使っている。しかし、製造業の中核データとなると話は別である。
コカ・コーラのレシピを知っている人は地球上に数人しかいないという。それと同じで、製造業にとってのCADデータやCAEデータは、門外不出のノウハウの塊である。特に、自動車、重工、精密機械、半導体製造装置、医療機器のような分野では、設計データの扱いはそのまま経営リスクになる。
だからこそ、オンプレミスでAIナレッジ基盤を構築するという方向性には意味がある。AIの性能だけでなく、データガバナンスと一体で設計されていることが重要なのだ。
AIの話になると、すぐに「人間の仕事がなくなる」という議論になりがちだ。
しかし、GADのようなシステムを見ると、少し違う未来が見えてくる。
AIがエンジニアを置き換えるのではない。AIが組織の記憶を補強する。優秀なエンジニアの判断を、次の世代が参照できるようにし、過去の失敗を、未来の設計で避けられるようにする。部署ごとに散らばった知見を、製品ライフサイクル全体で使えるようにする。
これは、かなり健全なAI活用だと思う。
人間が考えなくてよくなるのではない。人間が、過去の自分たちより賢い地点から考え始められるようになる。それが本来のナレッジマネジメントであり、生成AIが本当に価値を出す場所なのだろう。
生成AIの導入は、最初はチャットボットから始まることが多い。
それはそれでいい。入口としてはわかりやすい。でもほとんど役に立たない。
本当に重要なのは、企業活動の中で日々生まれる知的生産物を、AIが扱える形で蓄積していくことだ。
製造業でいえば、それは設計知である。
GHELIA AutoDeckが示しているのは、生成AIの次の段階である。
「AIに聞く」から、
「AIが知識を整える」へ。
「文書を検索する」から、
「設計意図を継承する」へ。
「属人化した匠の技」から、
「組織として再利用できる知識資本」へ。
生成AIは、単なる便利ツールではない。企業の記憶装置になりうる。
そして、記憶を持つ組織だけが、次の設計を少しだけ速く、少しだけ賢く、少しだけ失敗少なく進められる。
派手な話ではない。
しかし、こういう地味なところにこそ、AIの本当の価値は宿る。
GADに関しては、大手製造業を中心に問い合わせが殺到しているそうだ。
本当にお客さんが必要なものを作り出せたということだろう。
社員諸君、おめでとう。君たちの勝ちだ。