
September 13, 2024
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
先日、時価総額世界一に到達し、AI半導体で一強状態のNVIDIAに、司法省の捜査が入ったとの報道が複数の報道機関から報道された。
ロイター:エヌビディアに文書提出命令状、米司法省が独禁法調査本格化=報道
ただ、一方で誤報との噂もあり、落ち着かない。
ロイター:エヌビディア、米司法省から文書提出命令受けず 報道否定
とはいえ、NVIDIA一強時代に切り込むライバルたちもすぐ後ろに迫りつつある。
積年のライバルAMDはNVIDIA H100よりも大容量のMI300の投入を発表しているし、ここ数ヶ月はApple SiliconやCopilot+PCのNPUなど、非GPU系のマシンでも効率的にLLMを動作させることができるオープンソースツールが相次いで登場して話題を攫っている。
まさに群雄割拠といった佇まいだが、客観的にみてこのLLM半導体戦争において頭一つ抜きん出ている存在が二つある。一つはLLM専用プロセッサのLPUを擁する半導体ベンチャーであるgroqと、汎用データフローアーキテクチャーを採用したRDU(再構成可能データフローユニット)を擁するSambaNova(サンバノバ)だ。
これに加えてウェハーサイズの巨大なチップを標榜するCerebras(セレブラス)の三つが、特に推論に特化したチップ開発でNVIDIAのGPUを追い抜く勢いになっている。
中でも筆者が注目しているのはSambaNovaで、その理由はアーキテクチャの汎用性にある。
今回、シリコンバレーにあるSambaNovaのHQ(ヘッドクォーター)を訪れる機会があったので現地に赴き、実際に現場のエンジニアから直接SambaNovaテクノロジーの解説を聞く貴重な機会を得た。
写真は筆者(左)とアーキテクトのRaghu Prabhakar(中央)、他にも多数のテクニカルスタッフが参加するミーティングで個別に質問する機会を得た。
現在、通常のSambaNovaはGUIベースのSambaNova Suiteという環境が提供されているが、筆者はより低レイヤーのSambaNova DataFlowというネイティブ環境もテストドライブをした経験がある。
SambaNovaのDataFlowは、Pytorchベースのプログラムに少し手を加えるだけで任意のネットワークアーキテクチャをSambaNovaのRDU用にコンパイルできるようになっているが、低レイヤーだけに癖が強い部分がある。
しかし、今週からスタートしたSambaNova Cloudは、Meta Llama3.1-7Bを1100トークン/秒、405Bを114トークン/秒という高速度な推論を行えるという実力を示した。しかも、NVIDIA製GPUよりも高速かつ低消費電力であり、モデルのスイッチングコストもかなり低く抑えられている。
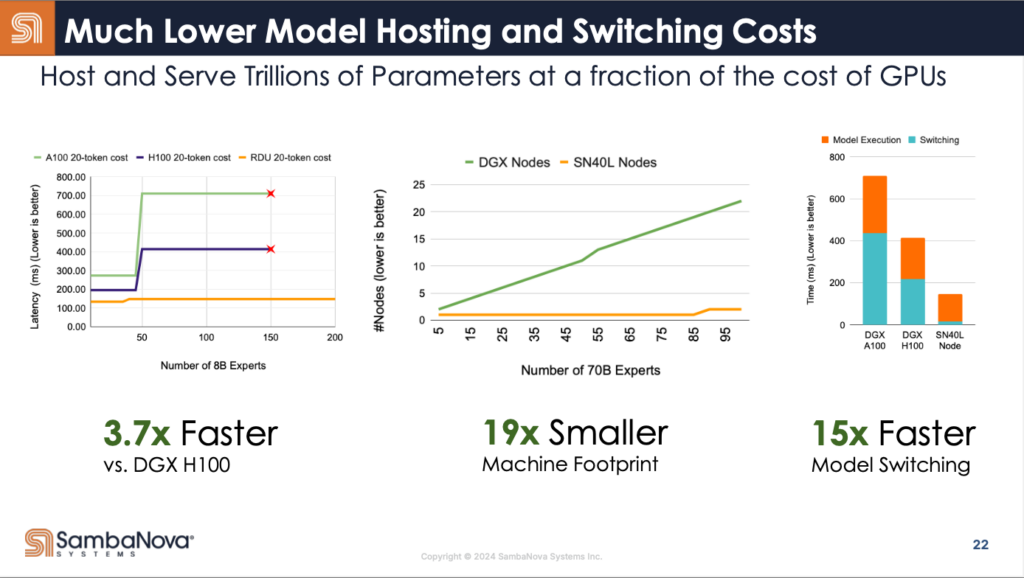
実際、SambaNovaの推論の速さそのものは、Webサイトで誰でも確認することができる。

この性能を支えているのは、SambaNovaが独自に開発した「データフロー」アーキテクチャである。
では、「データフロー」アーキテクチャとは何か?
簡単に言えば、「データが流れていく」ことによって計算を高速に処理する仕組みだ。
「それはCPUだろうがGPUだろうが同じではないのか」と思われるかもしれないが、実は全く異なる。
CPUやGPUの場合、データは、計算器とメモリの間を「行ったり来たりする」
これがいわゆる「ノイマン型アーキテクチャ」だ。
ところが、RDUのような「データフロー型アーキテクチャ」の場合は、データは原則として一方向に流れる。
小さい計算器と小さいメモリをデータが自由に流れていくというイメージになる。
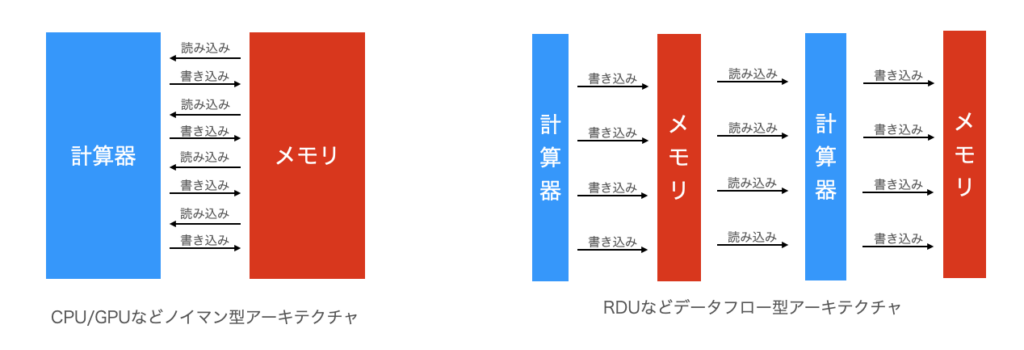
ノイマン型では処理すべきデータ量が増えてくると、計算器そのものの性能よりもメモリを制御するバスと呼ばれる部分、いわば「データが行き来する通路」が大渋滞を起こしてしまう。実はAIにおけるGPUの処理の大半は計算ではなくメモリアクセスのためのオーバーヘッドとも言われている。
それに対して、RDUの処理は、原則として一方向にデータが流れていくため、渋滞することがない。
大都市の道路が広い一方通行を効果的に配置することで停滞をなくしているのと同じ効果がある。
実際に、RDUのプログラミングでは、チップ上の物理的な配置をプログラミングすることで最も効果的なプログラムを書くことができる。
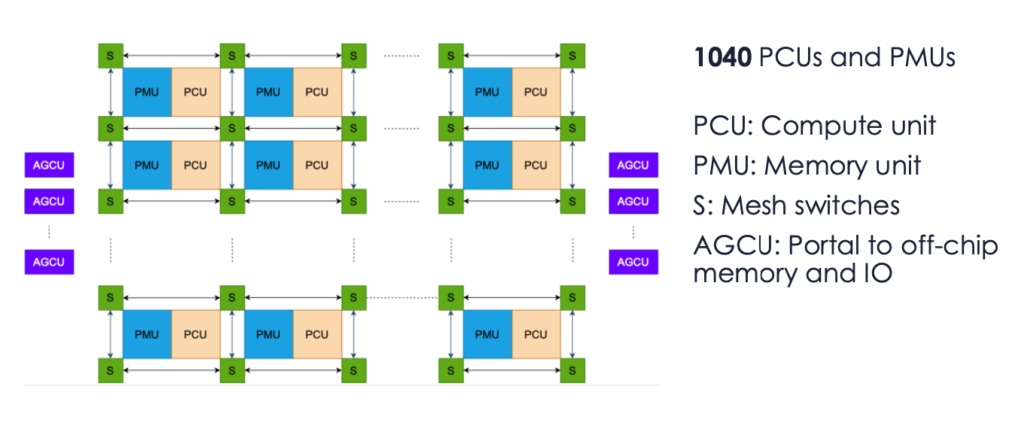
RDUでは、PMUというメモリユニットと、PCUという計算ユニット(計算器)がセットで配置され、このジオメトリをどのように設計するかで計算効率が大きく変わる。
先月シリコンバレーで開催された半導体の国際学会HotChips2024では、これまで謎に包まれていたSambaNovaの設計思想が詳細に解説された。
例えばAIの計算でよく使われるのは行列とベクトルの積和演算である。積和演算とは、「積(掛け算)」と「和(足し算)」を大量に繰り返す演算だ。
ほとんどのLLMの計算がこの積和演算であると言っても良い。この積和演算とデータフローアーキテクチャは相性が良いのだ。
AIの推論でよく使われるSoftmaxという計算について、実際にRDUに配置した例が以下の図だ。
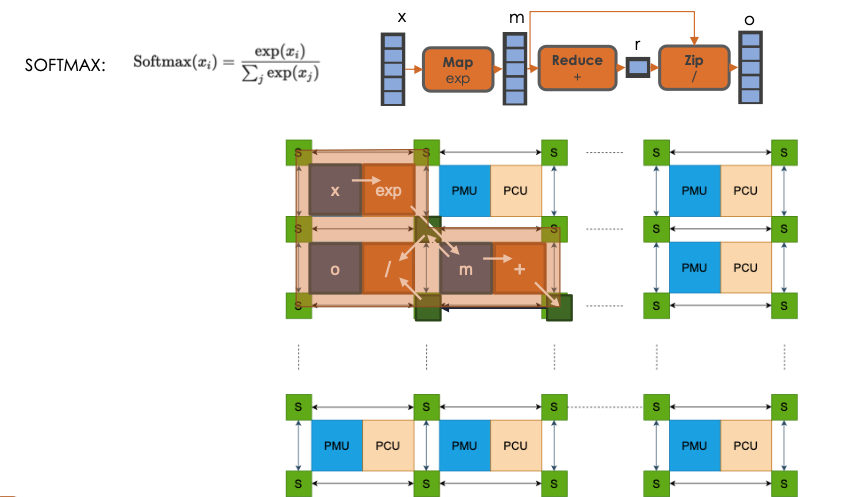
Softmax(xi)=exp(xi)/sum(exp(xi))で表される数式を処理する場合、左上の「x」の部分にx(というベクトル)が入力され、exp関数を通した結果を右下のmという部分に格納する。xをexpした結果をmを+(sum)した結果で割れば、Softmaxの計算が終了し、結果oが得られる。
この場合、わずか3ブロックの、しかも一方向のデータの流れで結果oを得ることができた。一度も手戻りがない。
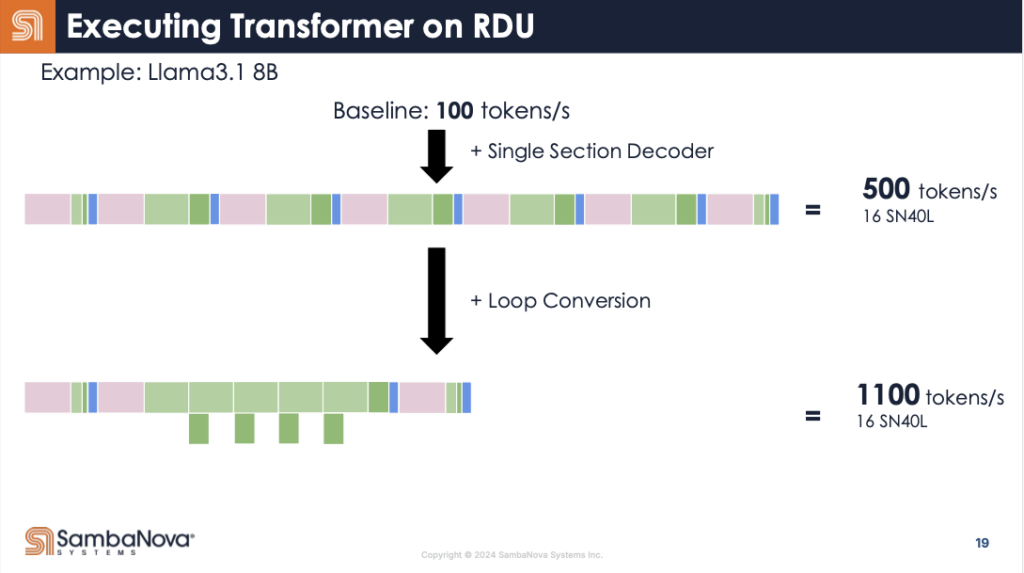
こうしたRDUの性質がLLMで使われるTransformerのようなモデルの場合、さらに有利に働く。
例えばLlam3.1のようなモデルの場合、Decoderというモジュールの計算を繰り返し行うことになる。

このデコーダの計算をGPUで行う場合、かなり複雑な計算をすることになる。
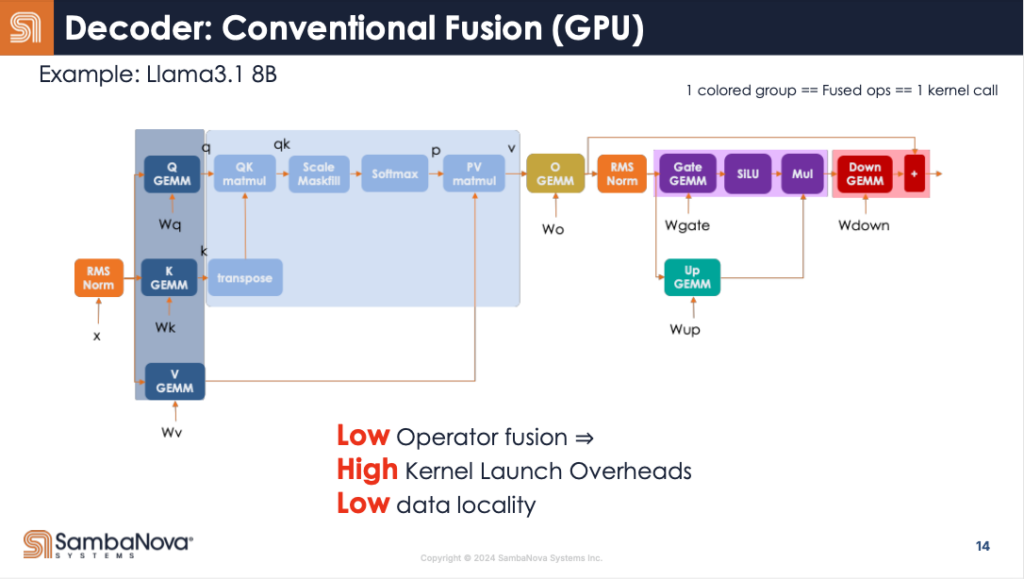
GPUでは、図で色分けされた部分ごとに毎回異なる処理をしなければならない。
ところがRDUでは、これが一回の処理で終わる。
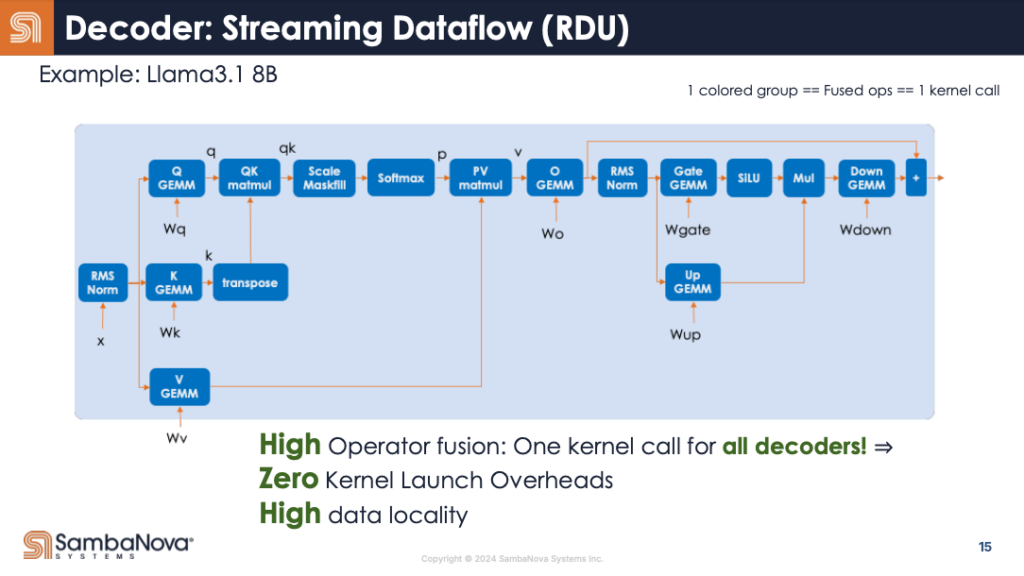
実際にRDUに配置すると下図の様な複雑なデータの流れになる。
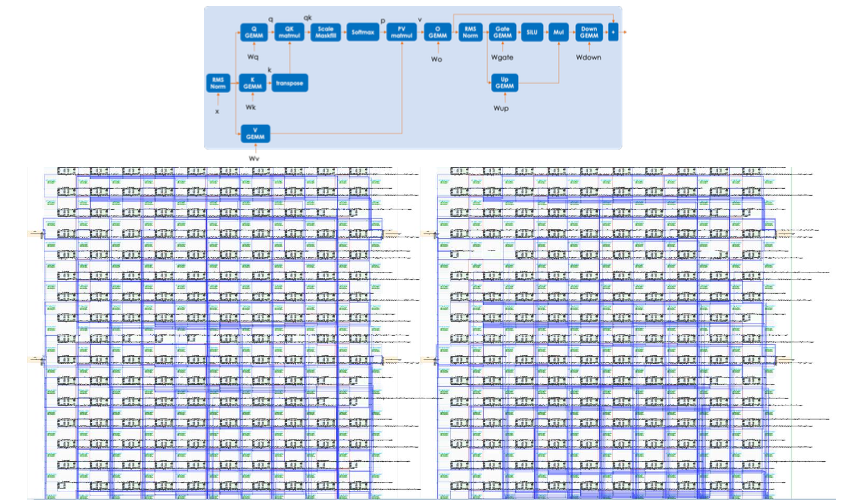
さらに興味深いのは、Transformerの場合、このデコーダを繰り返し呼び出すことだ。
RDUのデータフローアーキテクチャは、同じ構成の回路を複数回呼び出す場合、オーバーヘッドを劇的に減らすことができる。
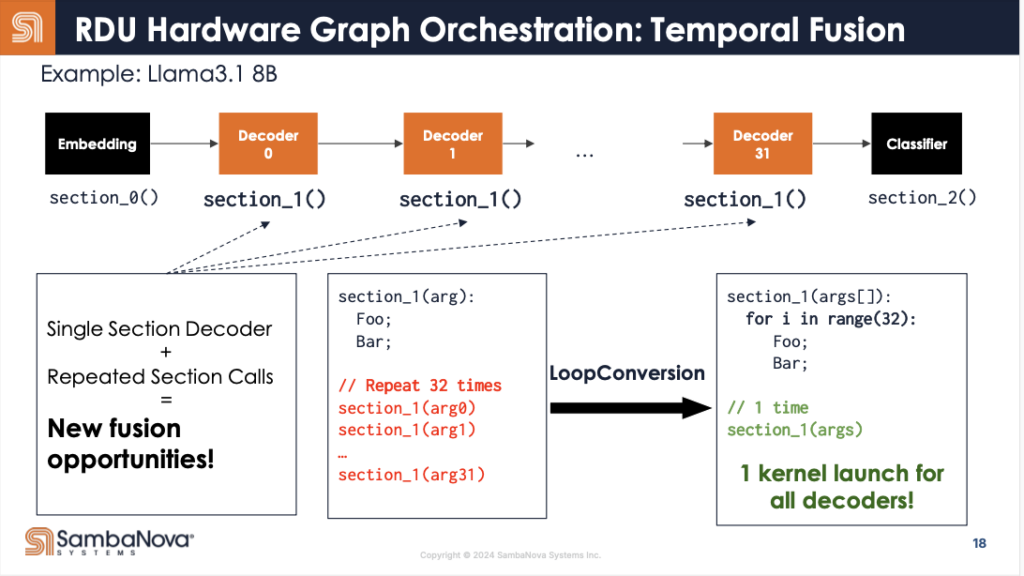
この最適化により、1100トークン/秒という驚異的な推論速度を実現しているのである。
今回、実際に本社だけでなくラボも見学させていただいた。

ラボでは、歴代のSambaNovaのチップに実際に触れる他、テストから出荷までの一通りの過程を実機を交えながら説明していただいた。
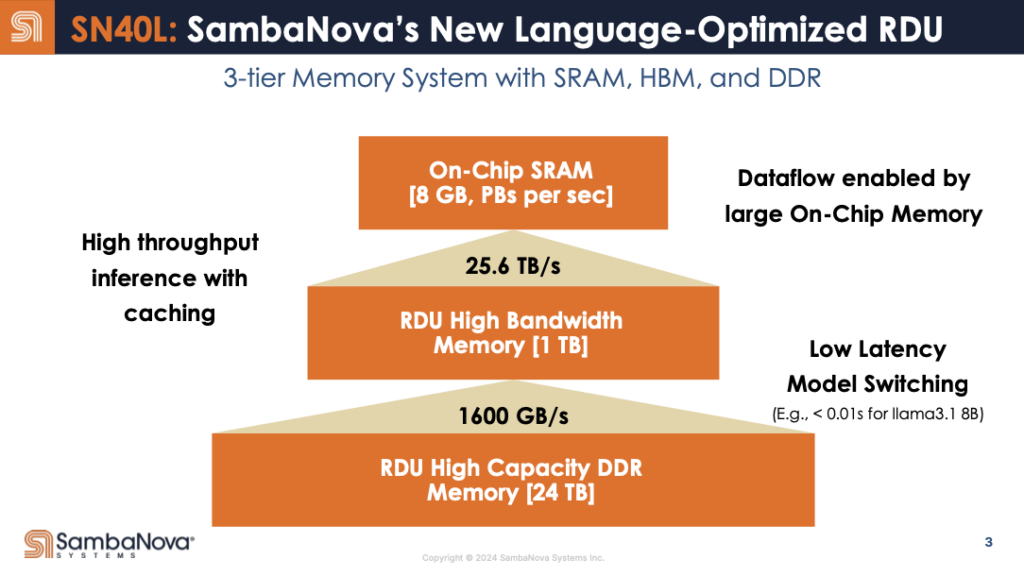
最新の第四世代RDU(SN40)では、GPUと同等のHBMメモリをも搭載し、極めて効率的なメモリ配置が行われていることが強調された。
短時間ではあったが、非常に実りある取材となった。
SambaNovaはこれまで、米国のローレンスリバモアやロスアルトスといった名門研究機関や米軍、日本国内では富嶽やソフトバンクなどに採用されてきたため、どちらかというと大企業や政府機関が顧客という印象が強かった。
しかし、今月から始まったSambaNova Cloudでは、GroqやChatGPTと同じ感覚で高速なLLM推論APIをエンドユーザーにも開放している。
料金が特段安いというわけではないが、高速化つ安定したLlama3.1のAPIサービスは一定の需要を満たすだろう。現在はLlama3.1しかAPIは対応していないが、今後は増えていくことが期待される。
どちらにせよチャンピオンの競争相手が現れるのは業界にとっても良いことだ。
今後も各社の動きを注視していきたい。