
original image: © sdecoret - Fotolia.com
May 25, 2017
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。

今年の人工知能学会の全国大会が名古屋で開催されています。
昨年の北九州市に比べると都会ということもあって心なしか昨年より盛り上がっているように思えます。
筆者も昨年に引き続き産総研主管のセッションに東大の松尾豊先生とともに登壇させていただき、深層学習の現状について話をさせていただきました。
松尾先生のお話の骨子は、AIの研究には、これまでのデータを学習することよりも、これからのデータを学習することが重要であり、製造業や農業といった現場にこそAIの導入が必要で、その分野であれば日本は世界と十分戦っていけるのではないか、と、大変勇気づけられる内容でした。
実際、筆者のもとに持ち込まれる案件では、店舗内の画像や工場内での画像、CTなど医療機器で得られたボクセルデータなど、そもそもネットで収集不能なデータが多く、どの領域でどのような学習が可能か、というのはまだまだ手探りの段階です。確実に言えるのは今のところ畳込みによる識別(画像に限らず、音声、波形などの識別)は既にかなりの精度にあり、十分実用可能な段階にあるということです。
松尾先生は最終的に「学習工場」というものが必要になると提言し、「学習工場」とは、学習用データと計算資源、そして人的リソースが一体化したものだと定義します。
その意味では筆者が経営するUEIも一種の学習工場に必要な機能を備えていることを講演の冒頭に紹介しました。

筆者の講演の中心テーマとしては、GPUリソースが慢性的に不足していることを指摘しました。
NIPSという機械学習の国際学会の〆切直前に全世界のGPUクラウドが枯渇するという事件が先日紹介されました。
NVIDIAが公表しているCUDAのダウンロード数は2016年時点で350万ダウンロードであり、この全てが個別の研究者ではないと考えられますが、1/3と見積もっても、一人一台として100万GPUの需要があることになります。

これに対して、Microsoft AzureもAmazonもGPUリソースが枯渇してしまって十分行き渡らないということになっています。

また、クラウドには別の難しい問題もあります。
それは、設備投資を回収するよりも前に新しい世代のGPUが登場してしまうというリスクです。
AzureやGoogle Cloud PlatformやAmazonが採用しているのはKepler世代がメインです。これはに世代前のテクノロジーなので、使用できるVRAMも計算速度も数倍おちます。さくらインターネットやIDCフロンティアが提供するサービスでは研究用途に限り安価なTITANXを使用できるので最新のチップを割安で利用することができます。
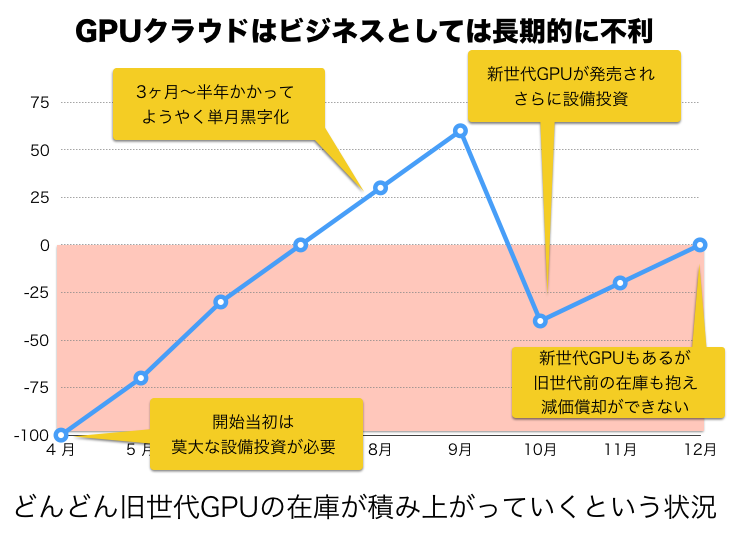
しかし、クラウドの場合、古い世代の在庫が大量に積み上がっていくというデメリットは見逃せません。
設備投資がかかることを考えると、ビジネスとしてはかなりの博打です。
その上、毎年、2倍以上の性能向上をした新世代のチップが登場するのです。
最近流行しているマルチノードの分散学習にも筆者は懐疑的です。

マルチノードで学習する場合、複数のノードで学習した結果をエポックごとに平均化する処理が必要です。
これがオーバーヘッドになります。

このオーバーヘッドを許容するためには、まずそれぞれのノードが同じスピードで計算しなければなりません。あるノードだけモタモタ計算していたら、全体の足並みが崩れるのです。
これに比べると、それぞれのノードがバラバラにハイパーパラメータを探索したほうが実はむしろ効率的なのではないかと筆者は考えます。

効率的なハイパーパラメータを見つけるほうが、ひとつの初期状態で乱暴に計算するよりも素早く高性能なAIを学習することができる可能性があがります。
実際、非常に簡単な問題の学習であっても、時間をいくらかけても無駄、ということがよくあります。
たとえば、簡単な論理回路、AND回路やXOR回路であっても、毎回性能が異なりますし、ぜんぜんダメなものもあればすぐに収束する場合もあります。
ということは、大きな学習であっても、初期パラメータがダメならぜんぜんダメということになります。
ならば、オーバーヘッドの大きいマルチノード学習をするよりも、ハイパーパラメータ探索を並列して行ったほうが良い場合が考えられます。
こういう用途に向いているのが、先日MicrosoftがBuild2017で発表した「Azure Batch AI train」で、APIを使うことで手軽に計算をクラウド上にオフロードできます。

価格も1GPUあたり1時間約1ドルなので、比較的リーズナブルです。
通常のクラウドと違うのは、セットアップなどは全て済んだ状態で、必要に応じてバッチジョブを投げることが出来るというところです。
深層学習研究でも、常に学習ジョブが走っていることは極めて稀ですから、手元で動作確認をしたらすぐにバッチジョブをクラウドに投げることが出来るというのはかなり魅力的です。
また、夜に開催されたMicrosoftとPFNのパーティでは、MicrosoftがChainerをワールドワイドでプロモーションしていくことや、ChainerMNをAzureで使えるように協力関係を築いていくことなどが紹介されました。

今後の動きにも注目です。