July 4, 2024
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
かなり長い間、本欄でも「AI(人工知能)」と書くときに、注釈として「AI(人工ニューラルネットワーク)」と書く必要があった。
というのも、AIという言葉が指す意味は範囲がとても広く、解釈次第ではただの電卓や辞書、IMEまでもがAIと呼べてしまうからだ。
だから、「AI」という言葉を多用する人を見た時、それは「新しいインチキ(Atarashii Inchiki)」であると考えた方が良いというジョークを言ったものである。
ここ5年で、事態は一気に変化した。今やニューラルネットワークでないものを「AI」と呼ぶのは憚られる。まあそれでもニューラルネット以前の古いシステムをいまだに「AI」と呼ぶようなIT(インチキ)企業は山ほどあるのだが、程度の低いところで満足している人たちにかまけているほど人生は長くない。
「古いAI」と「新しいAI」が「違う」のだということを一般大衆に広めるために「生成AI」という言葉を使うのも、本来は少し躊躇われるが、ただ、「ニューラルネットによるAI」とか「ディープラーニングによるAI」よりは遥かに一般の人がイメージしやすいので、「生成AI」という単語は我々、ニューラルネット派にとってはありがたい新語かもしれない。
さて、ニューラルネットにとって欠かすことができないのが「微分可能性」だった。
本校では以後、「AI」とはニューラルネットを指すことにする。
さて、AIを学習させるために必要な条件は微分可能かどうか、つまり微分可能性だった。
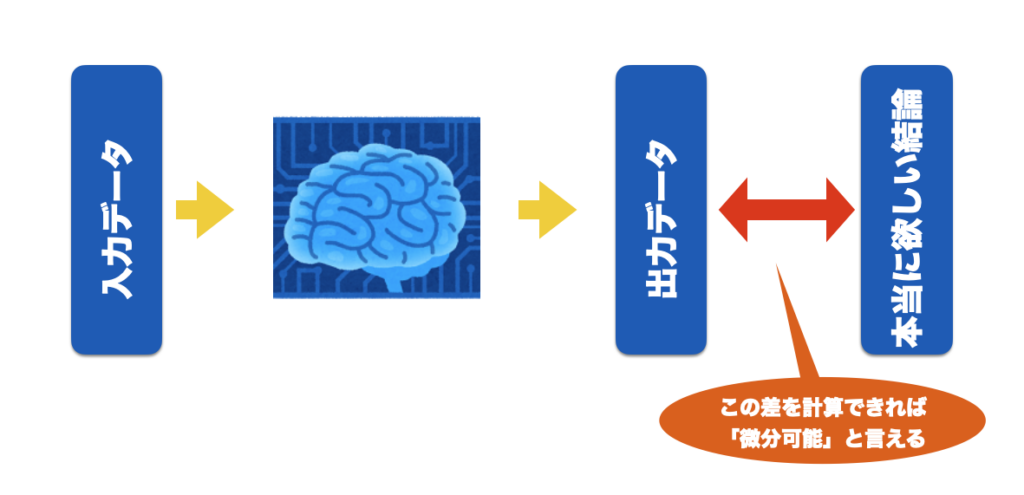
AIは、初期状態ではランダムな出力を出す。この出力は、数列である。この数列をテンソルと呼ぶ。テンソルは、1つの数値であるかもしれないし、画像データや動画データ、文章データなどかもしれない。いずれにせよこれらは全て「数値」の塊である。
AIへの入力もテンソルで行われる。つまり、数値の塊だが、それが画像でも動画でも音声でも構わない。AIとは、テンソルを入力してテンソルを出力するだけの仕組みである。
次に、ランダムに出てきた出力に対して、「本当はこういう結果が欲しかった」という「正解のテンソル」を与える。この「正解のテンソル」は、やはりテンソルであるため、画像や動画や文章かもしれないが、実は数値の塊にすぎない。
AIの出力テンソルと、欲しかった正解のテンソルは互いに微分可能でなければならない。この場合、微分とは、単に「差を求めることができる」ことを意味する。
「もっとこういう感じが良かった」というのを、数値の「差」として認識できれば、AIは出力から入力に遡って(遡及的に)信号を逆伝搬させ、その過程で「本来欲しかったはずの結果に近づけるための方向性(勾配)」を計算する。これが可能な環境を「微分可能プログラミング」と呼んだりする。
システム全体が微分可能に作られていれば、原理的にはなんでも学習できる。
しかし、世の中には全てが微分可能とは言えない場合がよくある。
例えば、カメラは微分可能ではない。カメラは現実の空間からレンズで集めた光を半導体素子に結像させるが、「本当はこういう写真が撮りたかった」という「正解のテンソル」を与えたとしても、カメラが現実空間に遡及して現実の方を変えることはできない。
カメラは極端なとしても、例えば一般的な3Dソフトは微分可能レンダリングをしてないので遡及的に学習することはできない。
近年はAIブームに関連して微分可能レンダラーや微分可能物理シミュレーションエンジンなどが登場した。これはこれで面白いのだが、微分可能にすると計算量も必要なメモリも極端に跳ね上がるので、よほどのモチベーションがなければ微分可能システムを作ったり使ったりするのは気が引けるのが現状だ。
今月末にコロラド州デンバーで開催される国際学会SIGGRAPH2024向けに投稿された論文で興味深かったものの一つが、ZeroGradsというものだ。
これは、通常の微分不可能なレンダリングエンジンで出力された画像であっても、「代理勾配」を計算することで学習可能にするというもの。
これまで「AIが学習するためには微分可能であることが不可欠」と思われていた時代と比べると非常に画期的なアイデアと言える。
似て非なるものとして、ここ一年繰り返し話題になる1.58ビット量子化モデルの学習手法も挙げられる。
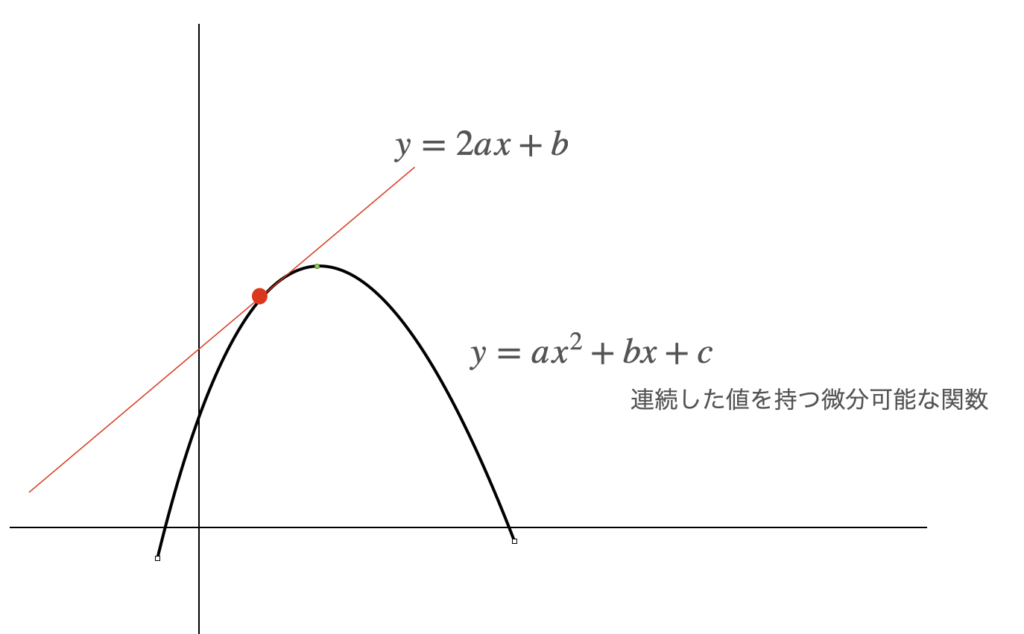
微分とは、本来、連続した値をもつ関数に対して行うものだが、1.58ビットに量子化するとかなり離散的な性質を持つようになり、解析的に微分することが不可能になる。
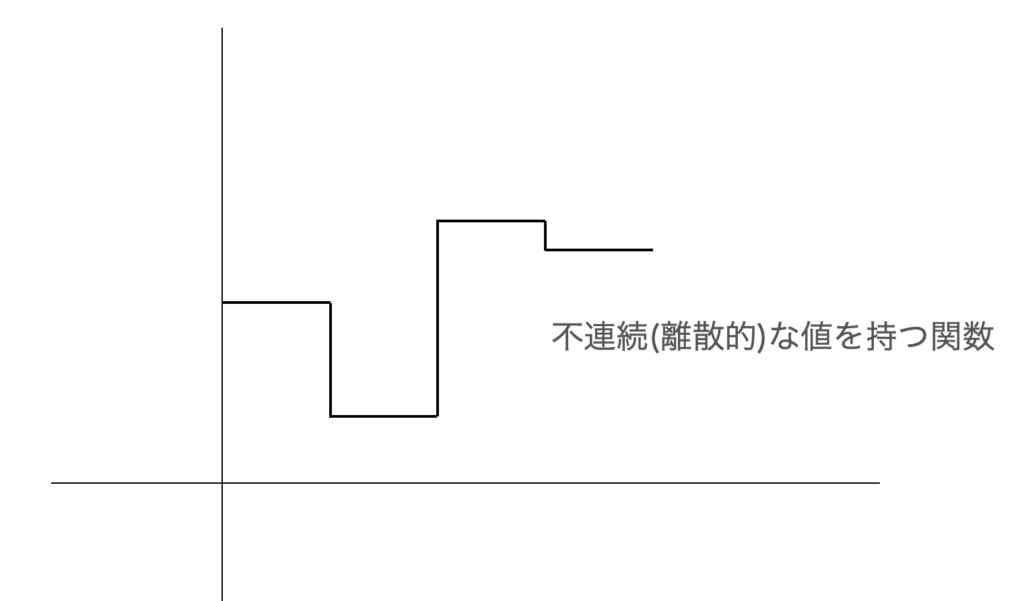
ただ、LLMをローカル動作させるには、現実的には量子化した上で推論させる方が電力的にも計算量的にも有利なので、できれば量子化させたいところだが、量子化したままの状態で学習するには、そもそも量子化された状態では微分不能であるという問題に対処する必要があった。
これに関ししも最近は量子化前提のトレーニング手法(QAT;Quantization Aware Training)の研究が進んでおり、必ずしも解析的に微分できなくても勾配の効率的な計算ができるようになる可能性が高まってきた。
そもそも、仮に解析的な微分をしたとしても、コンピュータは本来どこまで行ってもデジタルなので、実際には微分した結果をそのまま使っているわけではない。最終的には微分はある種の手がかりにはなるものの、実際には乱数を使って「それっぽい解」に近づいているので、もっと効率的な方法があっても良さそうなものである。
そういう意味では、最近のSakana.aiによるDiscoPOPのようなアプローチを見ても、実は人間が考えるよりもAIに考えさせた方が効率的な学習アルゴリズムが見つかるのではないかと思えてくる。そういえばGoogle/DeepMindのAlphaDevも、過去のどの人間が考えたものより効率的なソートアルゴリズムを発見したと数年前に話題になった。
AIの学習に微分可能性が必要なくなってくると、いよいよ本当にGPUが最適解なのかどうかわからなくなってくる。
もちろんまだまだGPUは必要だが、それがいつまでなのかは誰にもわからない。