ディープラーニングはビジネスにどう使えるか?
What do you get from deep learning?
Updated by 清水 亮 on May 20, 2015, 13:28 pm JST
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
人工知能の深層学習、いわゆるディープラーニングが話題となっています。
FacebookやGoogleがディープラーニング関連の企業を巨額で買収したニュースや、ドワンゴが社内に人工知能研究所を設置したニュースも記憶に新しいですね。
一体全体、人工知能とは何なのか、そしてディープラーニングとは何なんでしょう。気になっている読者諸氏も少なくないのではないでしょうか。
筆者はプログラマーとして、人生の中で幾度か人工知能や人工知能に近い振る舞いをするプログラムを書いたことが有りましたが、最近流行しているディープラーニングに関しては社員に任せきりで実際に手を動かして来ませんでした。
しかし、どうやら過去に二回到来した人工知能ブームとは根本的に異なるものらしいということがわかり、一体それがどういうものなのか、私自身も興味が出て挑戦してみることにしました。
すると驚くべき可能性が、このディープラーニングには隠されていると今更ながらに気付かされたのです。
ディープラーニングの有用性を理解するために、まず過去の人工知能ブームはどういうもので、なぜ失敗したのか、ということをおさらいしておきたいと思います。
第一次人工知能ブームが到来したのは1980年代でした。
この時は人間の神経細胞をモデル化したソフトウェア、いわゆる「ニューラルネットワーク」の可能性について研究されました。
人間の神経細胞はニューロンと呼ばれる細胞と、ニューロンから他のニューロンへと伸びるシナプスと呼ばれるもので成り立っていると考えられます。
あるニューロンが発火(情報を発信)すると、シナプスを通って別のニューロンに入力されるようなっています。情報を受け取ったニューロンは複数のシナプスからの情報を総合し、閾値(しきい値)を超えると自らも発火します。
学習は、ニューロンそのものではなく、シナプスの太さによって行われます。
こういう脳科学の仕組みがわかってきたので、これをそっくりそのまま、ソフトウェアで再現したら、なにかすごいことがわかるかもしれない、というのが第一次人工知能ブームでした。
実際にやってみると、いくつか有意な結果が得られるものの、根本的には複雑な認識ができないという欠点があることがわかりました。
欠点が明らかになってしまったため、このブームは一度沈静化はしますが、根気強い人々によって音声認識や手書き文字認識といった分野が発達しました。
現在、AppleのSiriなどが実現している音声認識は、この頃研究されていたものがようやく開花したものです。これは、1980年代ではまだコンピュータの処理能力やメモリが足りなすぎて、あまり複雑なことができなかったため、とも言われています。それが現代のコンピュータではいとも簡単にできるようになったので、携帯電話にも搭載できるようになったわけです。
SAMSUNGのGalaxy Noteや、UEIのenchantMOONに搭載されている手書き文字認識も、この頃の研究成果が結実したものです。
次に、第二次人工知能ブームがやってきました。
第二次では、脳の構造を完全に再現することはひとまず諦めて、むしろ人間がどんな言葉を認知しているか、という、知識ベース処理に興味が移りました。
自然言語処理とも言われます。
たとえば新聞記事やブログの記事を入力して、文章の意味をコンピュータに理解させよう、という研究です。
この研究の成果は、我々日本人なら必ずお世話になっている、かな漢字変換や後にRSSとして結実する、セマンティックWebと呼ばれる分野を生み出します。
ところがやはり知識だけ、言葉だけを理解したとしても、概念そのものをコンピュータが理解しているわけではないのでコンピュータが新しい知識を作り出したり、人間が気づかなかったことを指摘したりするのは難しい、ということになりました。
また、熟練した医師による問診をコンピュータがかわりに行う、「エキスパートシステム」も注目を集めましたが、実際に質問項目を考えるのは人間の仕事でした。コンピュータが答えるのはかなり早くなったのですが、肝心の人間が質問項目を考える作業が膨大すぎたり、進歩していく状況を常に追いかけるのが困難になったりして、結局、エキスパートシステムはなくなっていきました。
エキスパートシステムの成果は、例えばMicrosoft Officeを起動すると右下に出てくるイルカのようなものです。
誰もが「このイルカはなんのためにいるんだ?」と思ってしまうという、あのイルカです。
イルカは質問の意図を理解しているわけではありません。
ただ質問文を名詞や指示語や主語、述語に分けて(これを形態素解析といいます)、質問文の”構造”と目的語に対応するヘルプを探してくるだけです。
対話するようなふりをして実際には対話しないので戸惑うのです。
こうして過去二回の人工知能ブームは非常に重要な示唆を投げかけたものの、どことなく期待はずれと思われてしまう結果に終わりました。
では現在注目を集めている深層学習、デイープラーニングは何が違うのでしょうか。
例えば専門書にはこう書かれています。
「これまでの機械学習では、特徴抽出を人間の手で行っていたが、ディープラーニングでは、機械が自動的に特徴を抽出する」
これを理解するには、言葉だけ読んでもなかなか実感として湧きませんでした。
特徴抽出とは何か。
わかりやすくするために手書き文字認識で説明しましょう。
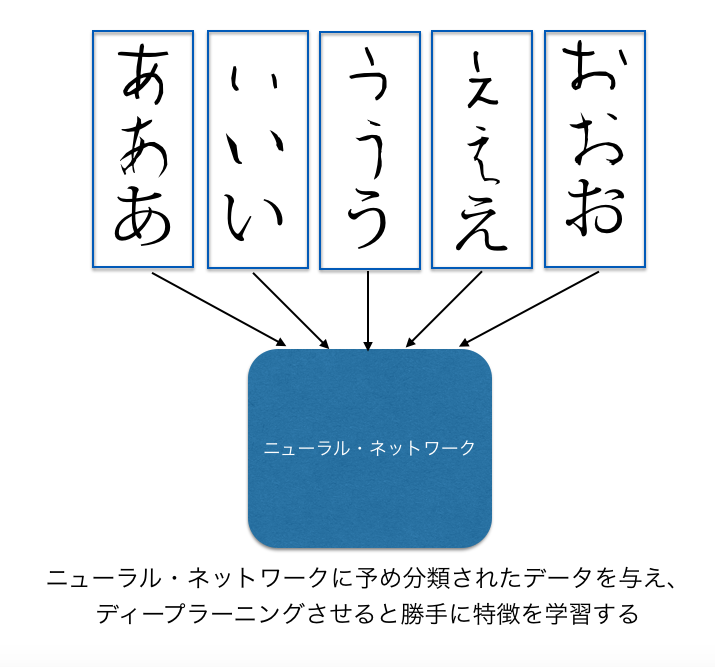
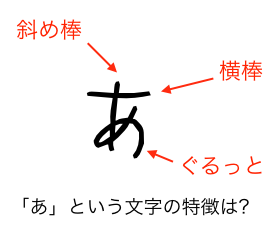
たとえばひらがなの「あ」という文字があるとします。
この「あ」という文字の「特徴」はどこにあるでしょうか。
よく見ると意外と複雑です。
横棒が一本、斜めの曲線が一本、全体を取り囲むように丸くなった線が一本で、これが複雑に交差しています。
「あ」という文字の特徴をひとつひとつ考えたり、それを全ての文字について人間が考えたりするのはいかにも無駄です。
そこで、まず「この特徴に注目したら、あとは機械が勝手に学習できる」という法則を人間が発見します。
あとは、「この特徴を持った文字は、”あ”だよ」と人間が機械に教えていくわけです。
この学習には、恐るべき時間がかかります。
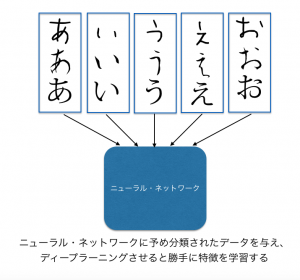
ところが深層学習では、適当に「手書きで書いた”あ”」や、「手書きで書いた”い”」の大量のバリエーションを入力し、学習させると、次にコンピュータが全く見たこともないような「あ」の画像を見せても、「それは”あ”です」と即座に判断できるようになります。
これまでは科学者が日夜頭を悩ませながら「文字の特徴はどこにあるのだろう」と考えて、試行錯誤を繰り返していた仕事を、コンピュータが勝手に覚えるのです。まるで幼児が文字を覚えるのと同じようなプロセスで。
実際の技術的な話は置いておくとして、今、第三の人工知能ブームが起きているのはそういうことなのです。
科学者達が数十年を掛けて研究してきた手書き文字認識ですら、ディープラーニングの練習問題になっています。
これまで莫大なコストがかかっていたことが、単なる練習問題になってしまったのです。これはブレークスルーといえるでしょう。今や人間側に高度な知識がなかったとしても、大量のデータをコンピュータに示すだけで、コンピュータが勝手に特徴を見つけて学習するのです。
これは控えめに言っても、驚くべきことだと思います。
さらに重要なのは、これまでの人工知能(特に第一世代の人工知能)で重視されていたのは、「認識」という機能でした。
これは人間や生物で言えば感覚器からの入力を捌く段階と言えます。
それだけでも、これだけ精度の高い音声認識や手書き文字認識が発達したのは恐るべきことですが、深層学習によるニューラル・ネットワークは、さらに上位層の「認知」機能を実現している可能性があります。
注意しなければならないのは、今の深層学習にできることは「認知」だけです。
認知したあとに論理的に思考するとか、判断するとか、残念ながらそこまではできません。
しかし、認知することそのものに価値を見出すことができれば、ディープラーニングは充分、実用的なものとして機能するはずです。
その前提として、ビッグデータがあります。
ディープラーニングはたくさんの情報を学習させればさせるほど、精度が上がると考えられています。
第一次人工知能ブームの頃にはデジカメ自体が存在しませんでしたから、そもそもコンピュータ上で画像認識するなとどいうことは、それ以前に大量の画像をコンピュータに取り込むという大変な仕事を、一体だれのお金でやるのか、ということが問題でした。
しかし今や、毎秒、世界中の人がFacebookやInstagramに画像をアップロードし、LINEで言葉を交わし、Twitterにつぶやいています。
つまり、誰かがわざわざデータを集めなくても、データが既にインターネット中にあるのです。
だからビッグデータを持っているGoogleや、Facebookといった会社や、大量の動画情報とコミュニティというビッグデータを持っているドワンゴが人工知能研究に熱を上げるというわけです。
ビッグデータを深層学習し、まずはそこから何らかの「認知」を得ることが目的です。
さて、しかし次の問題があります。
一体なにを「認知」できるようになると商売になるのか。ということです。
たとえばGoogleは、自社が運営するYoutubeの大量の動画データを1億円かけて1000台のコンピュータで深層学習し、猫を発見するニューラル・ネットワークを作りました。
これは人工知能の研究成果としてはとても凄いことなのですが、動画から猫を発見するのにお金を払う人は何人居るのでしょうか、というと疑問です。
また、その画像が猫であるかどうか、わざわざそんなお金をかけなくても、人間が見れば一発でわかります。
しかも人間の方がまだまだ精度が高いでしょう。
だいたい、今の深層学習の精度は高くても80%くらいです。
これでは、Googleの人工知能は10匹のうち、2匹を見逃してしまうことになります。
今、「ディープラーニング技術」というと、2つの方向性があります。
ひとつは、精度を上げるということです。80%を90%に、90%を99%に上げていくというものです。
これは非常に活発な研究分野で、コンテストも行われています。
成果が出れば論文にし易いので世界中の研究機関が夢中になっています。
もう一つは、「低コストで行う」ということです。
猫を認識するのに毎回1億円かかっていては話になりません。
計算を簡略化したり、高速化したり、適切なニューラル・ネットワークの構造を定義したりといった方法論でコストを下げていきます。
このどちらも、How(どのように)の研究と言えます。
しかしこの研究「だけ」では商売になりません。
たとえば想像してみてください。
自動車がない時代にエンジンだけが発明されるという状況を。
エンジンは物凄い勢いで回転運動を生み出します。
しかし、その回転運動だけを見た人は、「棒を回転させるって???これが何の役に立つの?回転してるのを見るのは面白いけどさ」
エンジンは自動車がなければ役に立つことが認知されません。
自動車があるからこそ、エンジンが役立つのです。
しかし今のところ、ディープラーニングには自動車にあたるもの、要するにアプリケーションがありません。
以前、京スーパーコンピュータの開発を担当された方にお会いした際、私は率直な疑問をぶつけました。
「一体全体、これだけの膨大なコンピューティングパワーを何に使うのですか?」
すると彼はこう答えました。
「それは使う人が考えることです」
もし仮に、京スーパーコンピュータを、ポンと渡されても、有効な使い道を思いつかなければ、京スーパーコンピュータを構成する建物はただの巨大な冷蔵庫です。
しかし実際にはコンピュータの世界ではしばしばエンジンだけが先に発明され、アプリケーションが発明されないということがよく起きます。
そしてエンジンを知らなければアプリケーションは作れず、アプリケーションを作らなければエンジンを理解できないのです。
私は実際に手元のコンピュータで学習させたり認識させたりしてみると、この「認知」能力を何に使うことができるのか、なんとなくイメージがつかめてきました。
たとえばカリフォルニア大学バークレー校で開発されたディープラーニング用パッケージのCaffeというオープンソースソフトウェアを使うと、どんな写真を見せてもそこに写っているものをなんとなく推定することができます。
これが非常に面白いデモになっているのです。
たとえば動物などはよほどのことがない限り正しく認識します。
しかし動物以外のもの、例えばマージャン牌や音楽スタジオ、アメリカ人の知らないであろう料理などを見せても、だいたい正しく推定できるのです。
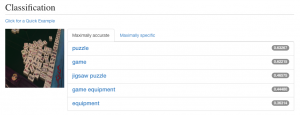
麻雀牌を初めて見たはずのコンピュータでも「パズル」までは認知できる
興味深いと思ったのは、「つけ麺」の画像を見せると、Caffeは「カルボナーラ」と反応したところです。

つけ麺の写真
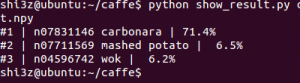
つけ麺の写真の分析結果
確かに、つけ麺はカルボナーラのようにも見えます。
実際にアメリカ人に見せたら、「カルボナーラ?」と反応するかもしれません。
ハンバーグという料理は、実はアメリカにはないのですが(驚くべきことにアメリカにはハンバーガーはあってもハンバーグはないのです)、ハンバーグの画像を見せるとミートローフと認識します。
以前、アメリカ人に「ハンバーグが食べたい」と言ってハンバーグの写真を見せると、アメリカ人は「ミートローフ?」と勘違いしました。実際には似てますが別の食べ物です。

ハンバーグの写真

ミートローフと推定されている
これだけでは何の役にも立たないように見えるかもしれません。
これでも80%程度の認識率なわけですから。
でも、このときニューラル・ネットワークが提供してくれるのは、「気付き」なのです。
私がこの結果にとても驚いたのは、私自身が意識していなかったけれども、私以外の存在が同じ事物を見た時に感じた「別の視点の気付き」なのです。
私は職業柄、常に「別の視点の気付き」を必要としています。
社内にコンピュータに疎い人間ばかりを集めた「カナリア隊」を密かに組織しているのもそのためです。
コンピュータに強いと、コンピュータに弱い、一般の人たちの視点をついつい忘れがちです。
だから「ふつうの人たち」を敢えて集め、コンピュータおたくにはない視点を常に求めているのです。
彼らとの会話は非常に刺激的で、毎回のように目からうろこが落ちる思いをします。
そしてそうした会話の積み重ねが、新しい気付きを与えてくれるのです。
私はディープラーニングされた人工知能に触れた時、彼らと接するのと同じような「気付き」が与えられることに驚きました。
「これは、こう見える」という情報に対して、「いや、こうも見えるんじゃないですか」という視点をコンピュータが提供してくれ、しかもなかなか侮れないのです。
「そう来たか」と思うような発見をコンピュータが提案してくれるというわけです。
人間のチェスのチャンピオンがコンピュータに負けてから久しいですが、実はチェスであっても、人間とコンピュータがペアを組むほうが、コンピュータだけが闘うより強いらしいです。
どういうことかというと、手を決定するのは人間なのですが、人間がコンピュータを使って、「ここに打ったら4手先はどうなる? 100手先は?」ということをコンピュータに聞き、コンピュータは人間が打とうとする手を先回りして計算し、教えてくれるというわけです。
これをハイブリッド・チェスと呼ぶそうですが、他の分野にもハイブリッド・チェスと同じように、人工知能が仕事を支援するということが出来そうです。
例えば予兆というのがあります。
ビジネスが失敗する予兆とか、成功する予兆とか、体調を崩す予兆とかです。
毎朝、自分の顔を撮影し、コンピュータが深層学習して覚えていきます。
ときどき、コンピュータはあなたの預金口座を確認したり、あなたの成績評定を確認したり、あなたの同僚や家族に「彼は最近どうですか?」と聞いて回るとします(迷惑なコンピュータですがここでは仮の話です)。
あるとき、あなた自身はなんとも思っていないけれども、コンピュータが警告を発してくれるとします。
「こういう季節になると、あなたは風邪をひきやすいので注意してください」
コンピュータには感情がないので、母親よりはむしろ的確にアドバイスを出すことが出来ます。
また、毎日顔を撮影しているため、あるとき、自覚症状のない病気になっているとき「お医者さんに行ってください」とアドバイスすることもできます。
これまでは、人間が注意深く認知機能を働かせていたことが、コンピュータの支援によって自動化することができます。その結果、人間の認知機能が働かなかったことによって起きるトラブルを軽減することができるかもしれません。
これはコーポレート・ガバナンスにも応用できます。
会社で社員の働きを見ていて、「こういう場合は、彼は疲れている」とか、「そろそろ彼に休暇を上げないと、大きな病気になるリスクが高まる」などということが通知できれば過労死も防げるかもしれませんし、横領や不正が行われている現場を察知することができるようになるでしょう。
マーケティング調査も通りいっぺんのアンケート調査ではなく、人々がアンケートの裏側に込めた本当の思いを読み取ることができるようになるかもしれません。
重要な視点は、認識の正答率を問題にするのではなく、正答率が低くても認知できれば利得があるテーマを見つけるということです。
それが発見されたとき、ディープラーニングは大きくブレイクしていくでしょう。
- Tags
-