October 13, 2021
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
テルアビブ大学が開発した、StyleGAN-NADAという手法が面白い。
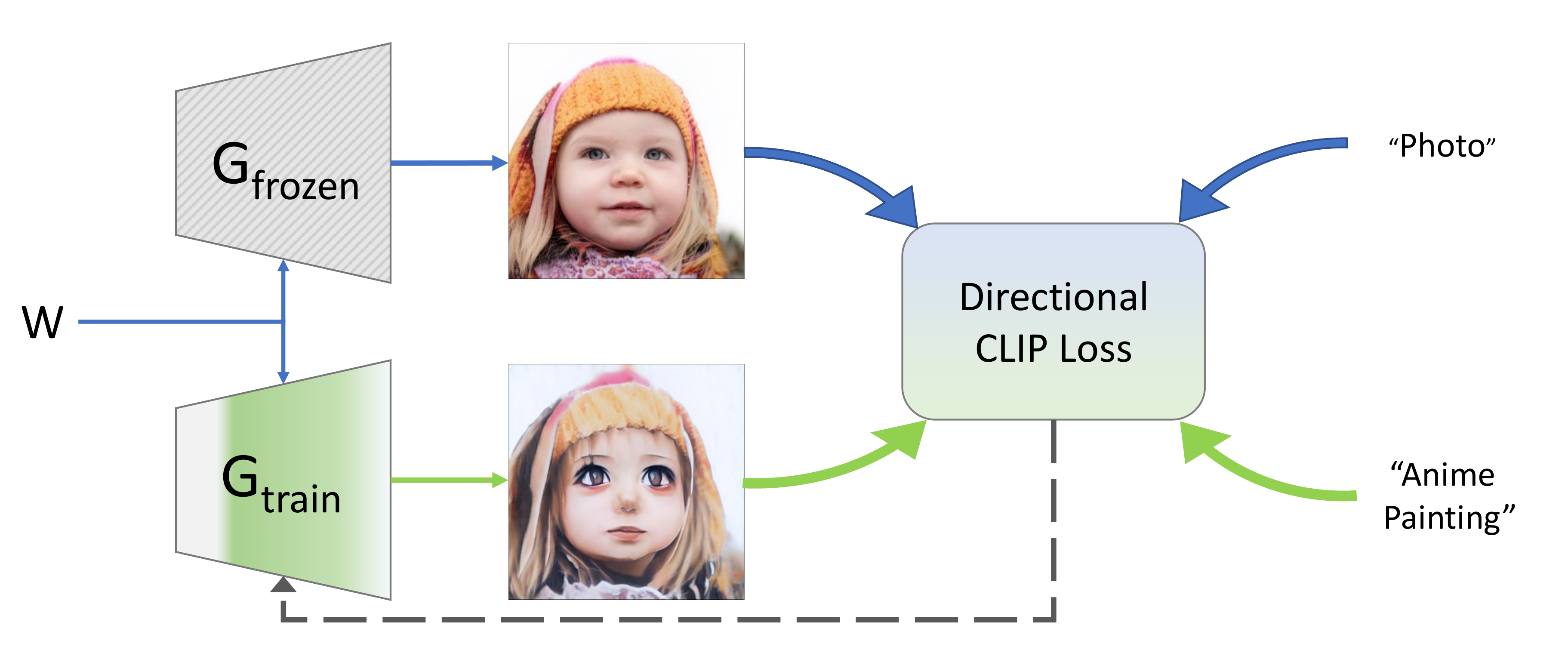
StyleGAN-NADAでは、一つの学習済みニューラルネットと二つの言葉を元に画像を生成する。
仕組みとしてはシンプルだ。一つの学習済みの画像生成ニューラルネットGを元に、学習しないGfrozenと、学習するGtrainを置き、そこに二つの言葉を与える。
たとえば、写真を生成する学習ずみニューラルネットならば、与える言葉の一つは「photo(写真)」となる。
つまりAIに「これは写真である」と教えてるわけだ。
次に、もう一つ与える言葉は、なんでもいい。「ブロンズ像」とか「ファンタジー世界のお姫様」とか色々あり得る。
与えられた二つの言葉を元に、Gtrainを学習していくと、さまざまな結果が得られる。

要は、Gtrainは、与えられた言葉に「寄せていく」機能を持っているわけだ。
実際にどんなことができるのか、筆者も色々試してみた。
まず、最初の写真の状態はこんな感じ。

この四人の顔そのものがランダムに自動生成されたものであることに注意されたし。
これに対して、たとえば「スケッチ」という言葉を与えると、こんな風な画像が生成されるようになる。
![]()
さらに学習が進むと、色がなくなっていき純粋なスケッチのようになる。

なぜかみんな、目の向きが向かって左側に寄っていくのは不思議だ。
たとえば「ブロンズ像」という言葉を与えると、こうなる。

面白いのは、元の学習済みニューラルネットワークが知るはずもないイメージを生成することだ。
たとえば今回使用しているFaceshqというデータセットは、顔写真のみを大量に学習したデータセットで、ブロンズ像やスケッチなど一枚も見たことがないはずだ。
にもかかわらず、それっぽい画像に寄っていく理由は、言葉を与えた時に、「言葉と画像の相関関係を導くAI」いわゆるCLIPというニューラルネットが、色々とGtrainに対して指南しているからだ。
生成するネットワークGは、本来は「過去に見たものと似たようなもの」しか生成できない。しかし、CLIPが言葉から連想される画像との違和感を示し、それを「微分」することで、Gは必死にCLIPの望むような画像を絞り出そうと頑張る。健気ではないか。
「日本人女性」という言葉を与えると、全員が日本人女性のように変化する。

そもそもFaceshqというデータセットには人種的偏りがあり、アジア人は少ない。だからこのGは、非常に頑張って「日本人女性っぽさってどういうことだろう?」と寄せていくのだ。
もちろんこれを全くフラットな気持ちで「単に数字上の変化が起きている」と考えることはできるが、筆者個人としては、AIが精一杯頑張っているように感じられてしまう。AIに魂がないことを百も承知の研究者であっても、AIの学習過程には感動を感じたり、感情移入したりする時がある。今回がまさにそれだ。
それでも無理難題をふっかけてみる。たとえば「ティン・トイ(ブリキのおもちゃ)」という言葉を与えると意外な結果が返ってきた。

実に興味深い。確かにブリキのオモチャはこんな感じの配色をしているように思える。
次に「人形」という言葉を与えてみる。

すると確かに人形のようになる。
無茶を承知で、例えば「ファンタジー世界のお姫様」を生成させようとすると
![]()
こうなる。
このプロセスはやはり感動的ですらある。
ただ同時に、物足りなさも感じる。
このAIは顔しか生成できないのだ。
その証拠に、たとえば「自動車」という言葉を与えると、意外な変化が得られる。

まず面白いのは、表情の変化である。
左上の男性は元の画像ではややぼうっとしているが、この画像では精悍で闘志に溢れたカーレーサーに見える。
一体これのどこが「自動車」なのかと思ってよくみると、背景が自動車のシートのように見えるものに変化している。
あたかも生成AIの”彼(または彼女)”が指南役AIのCLIPに「それじゃ自動車っぽくない!」とダメ出しされながら、必死に「自動車ってこういう感じですか!?わかりません!」ともがき苦しんでいる様子が目に浮かぶのである。
こうしたモデルの学習は意外なほど速い。10分程度で学習は完了し、新たに出来上がったGtrainは、無限にそれっぽい画像を生成できるようになる。
今年の初めにOpenAIが公開したCLIPは、非常に多様なバリエーションを産んだ。
最近はCLIPを他言語対応にしようという試みも多くある。
https://github.com/FreddeFrallan/Multilingual-CLIP
Multilingual-CLIPは、まさにそのまんまの名前だが、英語で訓練されたCLIPを多言語に対応させたものだ。
ちなみに元のリポジトリのipynbがバグっていたのでバグを直して日本語にも対応させたものがこちら。Google Colabで試せます。

単に翻訳したのではなく、「多言語」に同時に対応させた、という店が面白い。
つまり70以上の言語と画像の相関関係を同時に理解したCLIPが訓練されているのだ。
このように最近は言語を限定せず、最初から「多言語」を対象として学習するケースが多い。
この話の面白いところは、このやり方で学習させると、「英文1と英文2」の相関関係がわかるだけでなく、「英文1と和文1」の相関関係も計算できることだ。
筆者は個人的にTwitterで収集した数万件のワインのテイスティングメモ(主に英文)をもとに、日本語で「芳醇かつ爽やかな後味」のように入力すると、該当するワインが推薦されるという検索エンジンを作り、銀座でバーを経営しているソムリエに見せたところ、ソムリエも納得するような提案が返ってきて驚いていた。
そもそも、本職のソムリエであっても数万本のワインの詳細なテイスティングメモを常に頭に入れているわけではない。
まず産地や品種、作り手や畑と言った大まかな分類があって、その中で「いいワイン」「普通のワイン」というのを把握している。
この記憶方法だと、「産地も品種も違うが似たテイストのワイン」を見つけるのは至難の業だ。
だからブラインドテイスティング(名前を伏せられた状態でそのワインが何かを当てる)がソムリエコンテストの問題として出るのである。
ただ、この多言語化には課題もある。
そもそも、英語から他の言語に機械翻訳した言葉を学習させているため、それぞれの言語に固有の表現などは学習できないという問題がある。
たとえば、Multilingual-CLIPの例で、このような写真があったとき

それぞれいくつかの言語のキャプションとの相関性を求めてみる。

これで相関性を可視化してみると

確かに相関はしているようである。他の言語についても同様。
ただし、たとえば「リンゴ」を「林檎」に変えると、それが「りんご」であることは理解できないらしく、全くダメだった。

これが自動翻訳ベースのデータセットの限界である。
英語というのはさまざまな制約から表現力が非序に限られた言語である上に普及した言語でもあるため、「英語にはない表現」というものがしばしば他の言語には登場する。たとえば日本語で「もったいない」をそのまんま英訳するのは難しい。
また、データセットに対する文化的な解釈の違いもある。
しかしそういう個別の事情を考慮するととてもではないが70言語に同時に対応するというのは難しいので、今のところは機械翻訳と英語の文化圏から見た解釈を元にするしかない。
結局AIにとって一番重要なのはデータであり、「何が理想的なデータなのか」という問いは常にある。
そこにはそもそも「理想」の規定の背景にそれぞれの国や地域の文化・風土といったものがあるということを忘れてはならない。
ある地域では当たり前のものが、別の地域では非常識になる。
AIは進歩すればするほど、それを使う人間の想像力を要求してくる。
人類にはもっとイマジネーションが必要なのだ。