
August 15, 2021
清水 亮 ryo_shimizu
新潟県長岡市生まれ。1990年代よりプログラマーとしてゲーム業界、モバイル業界などで数社の立ち上げに関わる。現在も現役のプログラマーとして日夜AI開発に情熱を捧げている。
AIを研究する方向性は二つある。
一つは、AIを作ることによって研究する方法。これは通常の大学の研究室などで行われる。
新しい仮説を立てて、AIやデータを設計し、学習させ、どうなるか観察する方法である。
もう一つは、AIを使うことによって研究する方法。
これは主に企業で行われる。理論上は有効だと思われる方法も、実際に使ってみないと本当にどの手法がどこまで有効なのかわからない。
筆者の経営するギリア株式会社では、日々、AIを実用化した例が報告されている。するとわかるのは、最新の手法が必ずしも全ての状況に対して有効であるとは限らないということと、同時に最新の手法を踏まえなければ既存の手法もうまく活用できないということだ。
AIの世界では四半期に一回くらいは画期的な発見がある。つい先週まで最も良い手法だと思われていた手法が今日は時代遅れになる。
それはまだまだ我々人類が「知性」というものを正しく理解できていないことを意味する。
意外に思われるかもしれないが、AIの進歩というのは基本的に結果論でしかわからない。
ある仮説を立てて、その仮説通りにAIを設計し、実際に効果が高いことが確認できたとする。
通常の世界なら、これが確認できた時点で「その仮説は正しかった」と信じられる。数年から数十年くらいは信じられる。その後、もっと新しい科学的事実が発見されて、仮説の前提が間違っていたことがわかり、人類は真理に近づき、進歩する。
ところがAIの世界では、仮説通りにAIの性能が上がったとしても、本当にその仮説が正しいのかどうかわからない。なぜなら、数ヶ月後には全く新しい科学的事実が明らかになり、仮説が間違っていることがすぐに確かめられてしまうからだ。
だから、後から否定されるくらいなら、最初から「この仮説は正しいかどうかわからない」と考えておく方が精神衛生上好ましいとさえ言える。
たとえば、ディープラーニングの飛躍的成功の要因となった「畳み込みニューラルネットワーク」というのも、最近では必要性や正当性が疑われている。かといって、畳み込みに変わる最先端の方法に欠点がないわけではない。畳み込みはもともとメモリを節約するために考えられた手法だけあって実用的に使う分には問題ないどころか今でも有効かつ強力な手段であり続けている。
しかし誰もが「畳み込みは必ずしも知性の再現として正しくない」ことを知っている。知ったまま使っている、という状態である。
筆者が常に興味を持っているのは、AIに創造性が宿るかどうかだ。
文章作成支援するAIもあれば、作曲支援するAIも作画支援するAIもある。
こうしたAIがあれば、文章作成能力や作曲能力、作画能力のない人であってもそうしたものをAIの力を借りて作ることができる。
最近OpenAIが発表したcodexは、プログラミング能力のない人でも欲しいプログラムを言葉で伝えるだけでプログラムが自動生成されるというデモを行なって話題になった。
[youtube https://www.youtube.com/watch?v=SGUCcjHTmGY&w=560&h=315]
この動画では、AIが人間と会話しながらプログラムを書いていく様子を見ることができる。
「人間の絵を出せ」「よし、次にそれをカーソルキーで動かせるようにしろ」と指示するだけでそのようにプログラムが書かれる。まるで未来だ。
これを見て、プログラムが書けない人はどう感じるだろうか。
まるで魔法のように思える。自分にもプログラムが(書くのではなく)作れるかもしれない、と思うかもしれない。
しかしプログラムを書ける人間から見ると、これは全く、茶番である。
筆者はかつて、与えられたお題に対して9分でプログラムを書く、「9 minutes coding battle」というイベントを企画していた。
実際、少し訓練したプログラマーならば、9分でプログラムを書くことはそこまで難しくない。発想の瞬発力と集中力があれば大抵のことはできる。
たとえば、動画の中で「スペースキーを押したら人が上に行くようにしよう」と指示する場面がある。
すると、プログラムが追加され、確かにスペースキーを押すと人が上に向かうようになる。
しかしその動きは、とても単調なもので、このAIは「矢印の上キーではなく、スペースキーで人が上に移動するようにする」ということの意味を全く理解していないことがわかる。
普通、わざわざ矢印キーではないキーで人が上に移動する処理を書くとしたら、それはジャンプのような動きでなければおかしい。
結局のところ、このcodexではプログラマーは自分で書くよりも多くの無駄な時間を過ごさなければならない。最終的に仕上げるには、素人のプログラマーが書いたコードを修正するような過大なストレスを抱えることになるだろう。これだったら自分で書いた方が早い。
最近、言葉から絵を描くAIが再び盛り上がってきていて、筆者は最新の理論で絵を描くAIを誰でも触れるWebサービス「Gakyo」として無料で公開している。
このGakyoを使うと、手軽にすごい迫力のある絵を入手できる。
誰かが「重力特異点」という言葉を入れておくと、こんな映像が出てきた。
この絵が正しいのかどうかはわからないが、なんとなく「重力特異点」のように見えなくもない。
他にも、「ホログラフィック原理」という言葉を入れると、このような絵が出てくる。

一枚あたりの絵が出力されるのは5分程度なので、これなら絵が描けない筆者にとっては、「自分で書くよりも速くて綺麗」な絵が適当に手に入る事になる。
読書感想文ブログを書いてる筆者の友人などは、このサービスを使って読書感想文ブログの挿絵を書かせているそうだ。これは筆者からすると非常に驚くべきことで、なにしろ彼はつい昨年までガラケーを使っていたほどのアナログ人間なのである。
そのような人間にとっても「言葉を入力するだけでそれっぽい絵が出てくる」AIは使いやすいということなのだ。
しかしもう少し具体的な絵が欲しいと思うと、こういうぼんやりした指示ではうまく行かない。

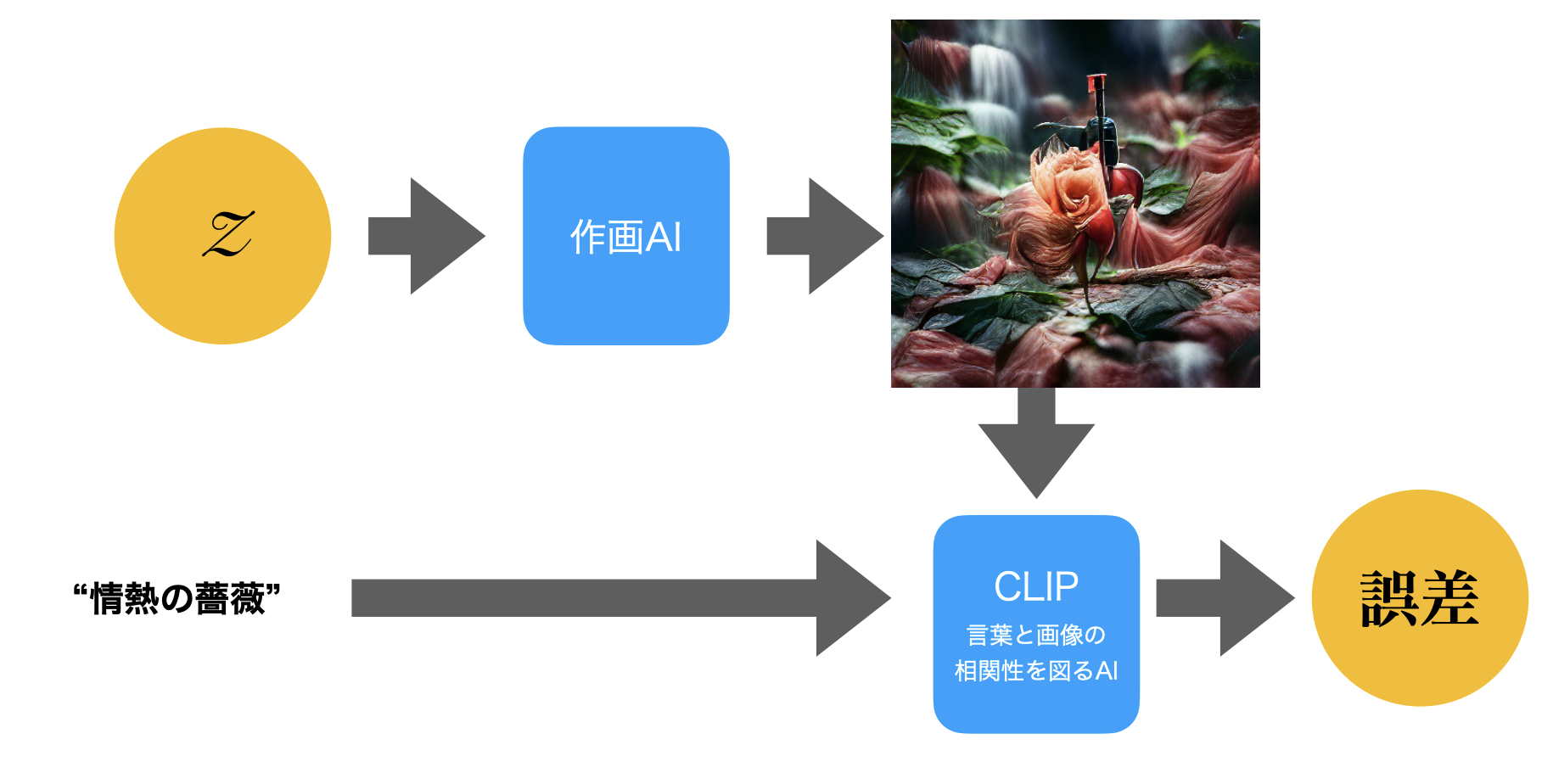
たとえばこれは「情熱の薔薇」を描かせたものだが、「情熱の薔薇」だけではこういう写実的な絵は出てこない。
筆者は写実的な表現を得たい場合に、世界的に有名な写真コンテストである「Hasselblad Masters」というタグを付け加えることにしている。この薔薇の絵もそのようにして生まれたものだ。画面の中央に機械的なものが見えるのは、おそらく「ハッセルブラッド」という言葉に反応したものだろう。

「東京」だけをキーワードに書かせると、こういうぼんやりした絵ができてしまう。
もう少し具体的なイメージにしたい場合、いくつかのキーワードを付け加える。

これは「東京2021」に、「by Masamune Shirow」というキーワードを加えたもの。
世界的に有名な漫画家の名前を加えると、出てくる絵の方向性がそちらに拘束されまとまりが出る。

これも同じテーマで「by John Berkey」としたもの。タッチの方向性がまるで変わることがわかる。

さらに幻想的な画風で有名な「James Gurney」というタグをつけると、全く異なるテイストの絵が出てくる。
原理を知らないと、何が起きているのか全くわからないかもしれない。
出てくる成果の素晴らしさとは裏腹に、このAIの原理は実にシンプルだ。
今年のお正月にOpenAIが発表した、「インターネット上にある言葉と画像の組み合わせの類似度を算出するAI」であるCLIPを用いて、AIがランダムに生成した絵と、与えられた言葉との類似性を計算し、得られた誤差(前回の記事で言えば微分を取ったもの)から、出力される絵の方向性を近づけていくのである。
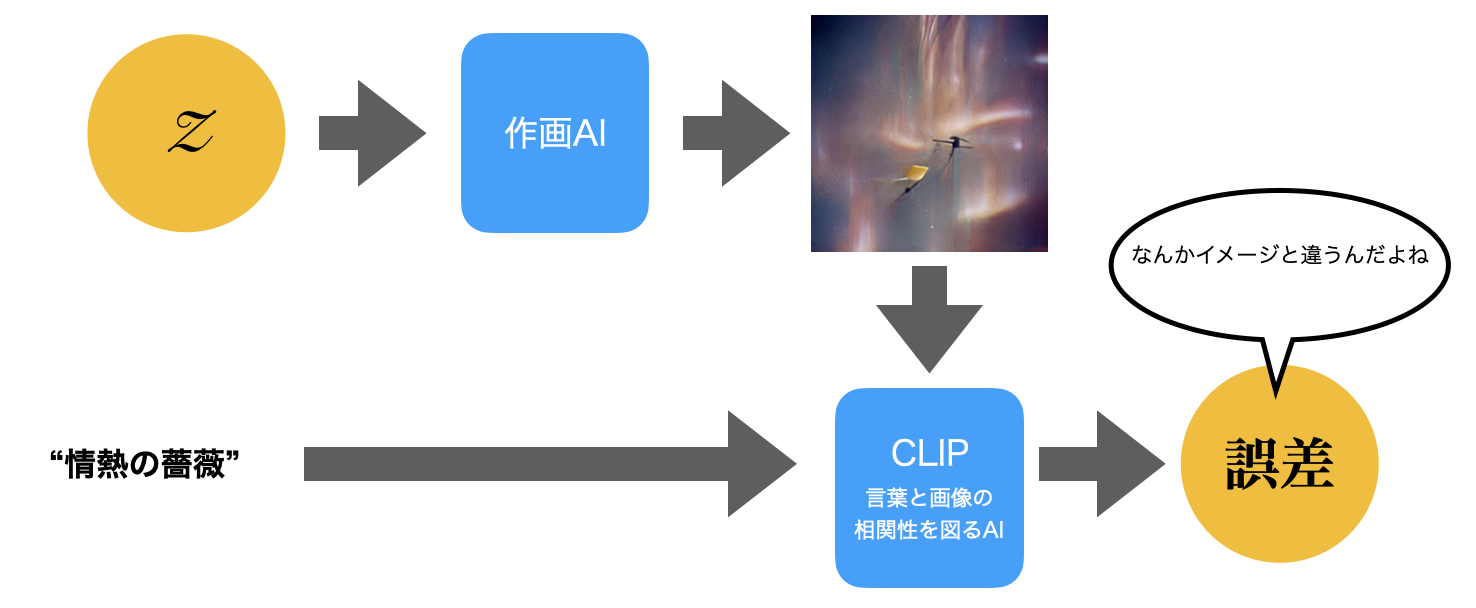
まず、乱数Zを元に、適当な絵を描く。この乱数Zは、本当に単なる乱数なので、制御しなくていい。
出来上がった絵を見て、CLIPが「与えられたテーマとは、この絵はイメージと違うなあ」という「違和感」を「誤差」という形で算出する。
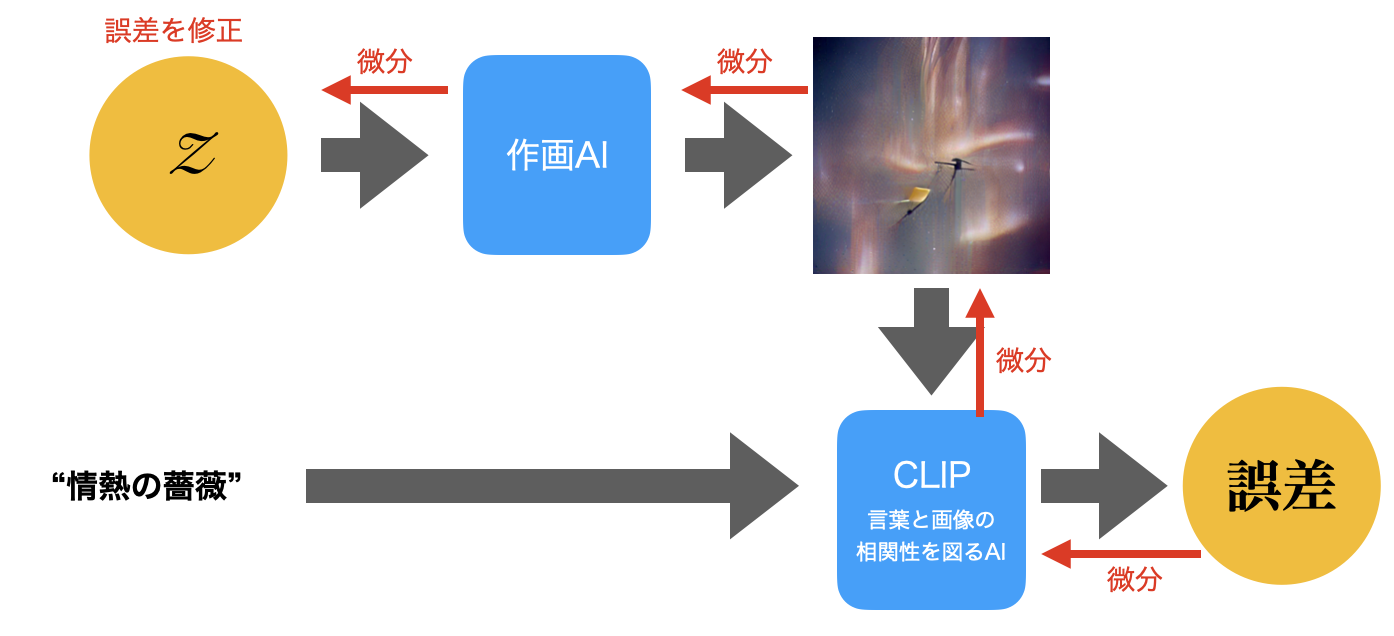
この「違和感」を微分して逆にたどっていくと、最初の乱数Zに行き着く。そもそも乱数Zは乱数であるのでいくらでも修正できる。
違和感を無くすように乱数Zを調整してCLIPで確認して違和感(誤差)を求めて、また逆伝搬させて微分してZを修正する、というのを繰り返す。
すると、だんだん違和感が減っていって、求めるテキストに近い絵が得られるようになる。
このような原理なので、どういうキーワードを与えるべきか、というのは、「こういう画風がいい」と思って作家の名前を与えてもいいし、「こういう傾向の写真が良い」ということで写真家の名前や媒体の名前を入れてもいい。
たとえば、有名な報道写真家集団「マグナムフォト」を加えて新宿ゴールデン街を描かせるとこうなる。

こうしたAIを使う我々に求められるのは、まず第一に、絵や写真に対するリテラシーだ。
こうしたものに対する基礎的な教養がなければ欲しい画像を手に入れることはできない。
もう一つ、そもそも今のところCLIPは英語にしか対応していない。そのせいで、基本的に海外の画家や写真家や、日本人であったとしてもかなり限定的な作家だけが画風としてフィーチャーできる。
しかし、たとえば日本的な漫画のようなものが欲しいのであれば、漫画に関する知識をCLIPに学習させる必要がある。
次に、そもそもAIは「誰かの画風」を真似できたとしても、「画風そのもの」を自分で作り出すことは今の所できない。
いや、実はできないとは言い切れない(前述のように仮説は常に間違っていると考えるのがこの業界の常識だ)。
たとえば「ミュシャとJohn Berkeyを足した画風」は作れる。

ちなみに、ミュシャを70%、岡本太郎を30%みたいなこともできる。
ただ、やっばりこれではどこまで行ってもそれを超えることはできない。
この先は、人間の創造性とは何なのか。
非常に難しい領域に踏み込むことになる。
どんな人間でもまったく先人の影響を受けずに絵なり音楽なり文章の達人になることはできない。
多かれ少なかれ、色々なものの影響を受けていないはずがないのである。
現役の作家でさえ、常に色々なものの影響を受け、それが作風に反映されるのが普通だ。
だから「ミュシャと岡本太郎を3:7で足したようなもの」はオリジナルの画風である、と呼べば呼べなくもない。それに意味があるのかどうかはわからないが。
このAIを使って自分なりの画風を実現するには、CLIPを自分なりに再学習したり、今回は説明が面倒なので省いたが、絵を生成するVQGANを自分の独自のデータセットで学習させたりとか、そういう風にしなければならないだろう。
しかし反対に、このAIは(今のところ)人間の顔とか体とかを具体的に描くのは苦手である。
それは、乱数からスタートして、単なる相関性だけで、言ってみれば「大雑把な印象だけ」で絵の良し悪しを判断しているので、「それが絵として正しいか」「人間が正しくデッサンできているか」という指標は持っていない。もちろん、その指標を持たせれば、それなりにうまく行く可能性はある。
その意味でまだまだ発展途上な技術であることは間違いない。
少なくとも「言葉を元に絵を描くAI」というジャンルは今年に入って爆発的に進化が加速している分野なので、また三ヶ月もすればさらに画期的な成果が出ている可能性もある。
絵を描くということと、プログラムを生成するということ、似ているようでいて似ていないと筆者は感じる。
それは筆者がプログラムを書くことができて、絵を描けないからだけではないように思える。
二次元の平面に制約される絵に比べると、プログラムは表現できる可能性が広すぎる。そもそも論理的に破綻していたらプログラムは動かない。
AIが自動生成したプログラムが論理的に破綻せずに動くのは凄いことなのだが、どうももう一つ魅力に欠けている気がするのである。何となく、プログラミング教室で子供の肩越しにプログラミングさせてるような、もどかしさがある。
ところが絵に関していうと、論理的に整合性が取れていなくても雰囲気だけで非常に美しいとか、魅力的に映る絵がどんどん出てくる。この違いは一体なんだろう。
この分野のさらなる発達に期待したい。